
Kafka整理
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/MQ/kafka-remark.html
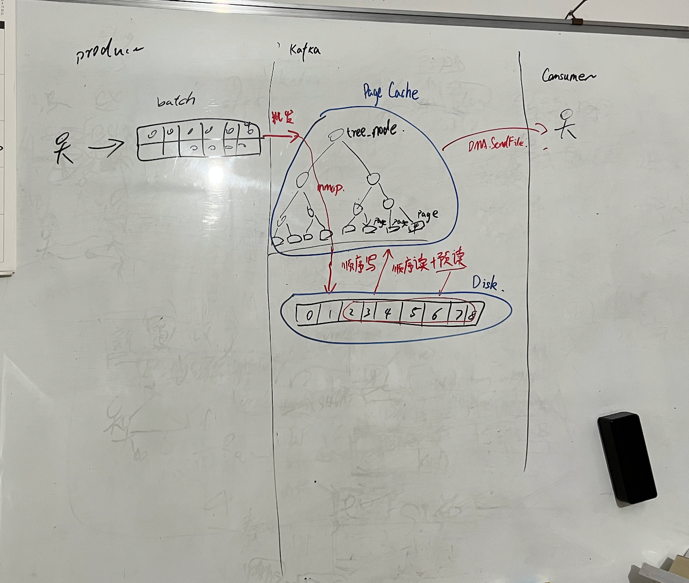
kafka为什么快
1. 通过生产和缓冲区减少网络开销
生产者发送消息时,会将多条消息打包为一个batch(发送缓冲区)一起发送,等缓冲区大小达到阈值或者一定时间,批量发送
2. 根据不同ack配置,可以不刷盘、少刷盘就响应ack
ack=0
生产者发送消息后,不会等待Broker的响应,不保证消息是否到达Broker
ack=1
生产者发送消息后,等待Leader Broker接收到消息后,返回ACK响应。
acks=all或acks=-1
生产者发送消息后,等待Leader Broker接收到消息,并且等待其他所有副本都成功复制消息(落盘),才会返回ACK响应。
注
节点接收到数据后不会立马刷盘,会先暂存到pagecache里,等到一定的大小或者时间后才会刷盘
3. 零拷贝
- 正常IO需要经过5次读写才能从磁盘读取数据发送给消费者
- 零拷贝可以实现内核态之间硬件的数据拷贝,只需要2~3次IO,尽可能不需要经过应用态,减少了2-3次非必要IO,也减少了用户态内核态的切换
kafka实现延迟队列
1. 分级主题循环等待
- 正常生产,消费时如果时间不到,丢回队尾
一般采用相同(如10分钟)级别的delayed-messages,以免前面的消息堵塞后面的数据
2. 生产者方延迟发送消息
- 生产者生产延迟消息丢到第三方存储
如Redis/RocksDB中,再启动异步线程任务将过期消息丢到目标主题完成延迟消息的消费
顺序消费
1. 单个分区+单个消费者
问题:慢
2. 多个分区+多个消费者
借助partitioner,把有先后顺序的同个业务单分到同个分区消费
需要注意的问题
- 阻塞问题
消息处理失败最好不要在消费时候重试或者等待,以免阻塞后面的数据
如:消息消费时,先查一下重试表有没有这个单号的数据,没有就正常消费,否则保存到重试表让重试逻辑自己处理
处理积压数据
各个partition数据分布不均
各个partition数据分布不均,个别因为数据分区规则导致个别partition数据量很大,而一些又很小
- 优化分区规则,如:把分区号由城市改为订单号
消息体过大、非必要消息量过多,导致IO问题(kfk2次网络IO,2次磁盘IO)
优化消息体与减少消息量
因为促销等业务高峰原因
1. 消费时改为多线程消费
2. 改代码:
- 消费并发布到新主题,新主题的分区数为原来的3倍
- 原业务代码开3倍的消费者消费新的主题
慢,麻烦,有风险,需要新机器*2
3. 消费者用高性能机器替换
这里以后最好可以做好风险预案,做动态线程池
保证消费数据不丢失
1. 生产者
ack!=0,确保至少落到Leader Borker的磁盘后才给生产者ack
2. 消费者
保证至少是At-least-once消费模式
1. at most onece模式
- 禁用自动提交偏移量
- 接收到消息立马ack,然后再处理
2. at least once
- 禁用自动提交偏移量
- 接收到消息先处理,再提交偏移量
3. exactly once
- 禁用自动提交偏移量
- 处理消息 & 提交偏移量 & 保存消息id信息到第三方存储
注: 需要在同一个分布式事务管理器
补数
配置上(重置偏移量)
消费者配置中,KafkaConsumer 类的 setProperty 方法设置『auto.offset.reset』配置:- earliest,重头消费
- lastest,从当前消费(默认)
- none,当前消费者组没有偏移量,报错
业务上
- 重置偏移量
- 上游重发
- 将需要补数的数据暂存到其他新主题,或外部存储,后续用特殊新逻辑重新消费
自动提交偏移量(enable.auto.commit)
默认打开
在默认情况下,消费者会在每隔 5 秒钟的时间内将最近一次已消费消息的偏移量提交给 Kafka 服务器
如何保证高可用
- 多副本数据冗余,保证数据『高可用』读写
- ISR(In-Sync Replicas)机制,只有同步了Leader的副本才可以参与读写,保证了数据的『一致性』
- zk保证broker的『可用性』,当broker上下线、宕机,可以实现『分区自平衡』
- 持久化机制
- leader机制,kafka一个分区有一个leader+多个follower副本,leader负责读写,故障会选举出follower作为新的leader
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 花火笔记!
相关推荐
2019-05-28
Spring生命周期
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Spring/Spring-life-cycle.html 以以下为准: 1. 获取beanDefinition 通过loadBeanDefinitions() -> 读取配置文件 -> 解析配置文件 -> 封装成BeanDefinition -> 注册到BeanDefinitionRegistry的beanDefinitionMap中 扩展1:BeanDefinitionRegistryPostProcessor.postProcessBeanDefinitionRegistry 获取BeanDefinitionRegistry,增删改BeanDefinition,因为后续按此顺序创建 扩展2:BeanFactoryPostProcessor.postProcessBeanFactory BeanDefinition加载完成之后,但实例化bean之前进行一些额外的处理 这时候所有的bean定义都已加载,但还没有实例化任何bean。...
2019-05-22
【Spring源码分析】循环依赖的处理
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Spring/Spring-Circular-Dependencies.html 看源码的同学可以查看我的GitHub 上面在官方的基础上加入了大量中文注释,帮助理解 要了解的知识 什么是循环依赖 graph LR A-->B B-->C C-->A 存在哪些循环依赖 Setter循环依赖(可以被解决) 构造循环依赖(报错) 基于Prototype类型的循环依赖(报错) Bean的创建步骤 看源码的同学可以找到源码: 环节1~4的代码在AbstractAutowireCapableBeanFactory#doCreateBean方法中 环节5的代码在DefaultSingletonBeanRegistry#getSingleton(String,ObjectFactory)方法的addSingleton(beanName, singletonObject);中 Spring是怎么处理循环依赖的(对于单例Bean) 实现原理 Spring在创建...
2021-01-12
消息中间件-kafka
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/MQ/mq-kafka.html 1. 为什么 Kafka 快 1.1 通过生产和缓冲区减少网络开销 Kafka 的生产者发送消息时,会将多条消息打包为一个 batch(发送缓冲区)一起发送,等缓冲区大小达到阈值或者一定时间,批量发送,从而减少网络开销 1.2 根据不同 ack 配置,可以不刷盘、少刷盘就响应 ack ack=0:生产者发送消息后,不会等待 Broker 的响应,不保证消息是否到达 Broker ack=1:生产者发送消息后,等待 Leader Broker 接收到消息后,返回 ACK 响应 acks=all 或 acks=-1:生产者发送消息后,等待 Leader Broker 接收到消息,并且等待其他所有副本都成功复制消息(落盘),才会返回 ACK 响应 **注**: 节点接收到数据后不会立即刷盘,会先暂存到 pagecache 里,等到一定的大小或者时间后才会刷盘 1.3 零拷贝 正常 IO 需要经过 5 次读写才能从磁盘读取数据发送给消...
2019-12-12
Spring常见事件
[转载]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Spring/Spring-events.html ContextRefreshedEvent:表示ApplicationContext已经初始化或刷新完成时触发。通常在应用程序启动时使用,用来执行初始化操作 ContextStartedEvent:表示ApplicationContext已经启动时触发。通常在应用程序启动时使用,用来执行一些启动任务 ContextStoppedEvent:表示ApplicationContext已经停止时触发。通常在应用程序停止时使用,用来执行一些清理任务 ContextClosedEvent:表示ApplicationContext已经关闭时触发。通常在应用程序关闭时使用,用来执行一些清理任务 RequestHandledEvent:表示Web请求已经处理完成时触发。通常在Web应用程序中使用,用来记录日志或统计数据 ApplicationStartedEvent:表示Spring Boot应用程序已经启动完成时触发。通常在Spri...
2099-09-05
每天进步一点点 - 基础技术篇
[原创]这篇只是做点记录备忘,个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Make-A-Little-Progress-Every-Day/Make-A-Little-Progress-Every-Day-Basic-Technology.html 本文不怎么更新了 2022-10-25 目前本地缓存使用的方式 订运单系统: SF自研的类Ehcache框架,存储的内容不是特别多,都是一些网点月结卡号信息,所有对象存在于Map,占200m左右 SISP系统: 使用了Caffeine,存储的内容,存储的内容很多,包括员工表(900m),人员表(bdus 800m) 客户表(1.2g),用户及权限相关表(500m) 关联后约占4g内存,目前采用Caffeine默认存储方式,启动即全量加载(极个别采用懒加载方式加载),全部存在于Map中,即堆存储 优化: 缓存为基础数据,数据量稳定,目前采用CMS回收器,堆空间8g,缓存存于堆中,占约4g,平时MajorGC达4~6s,曾出现高峰gc达52s, 应考虑将缓存存于堆外...

2019-01-09
MQ常见问题及其处理方案
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/MQ/mq-common-problem.html 基于Rabbitmq:
