

每天进步一点点 - English
[原创]这篇只是做点个人英语学习的记录,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Make-A-Little-Progress-Every-Day/Make-A-Little-Progress-Every-Day-English.html 2025-12-11 Vocabulary Sentence - conversation Just updating is enough. (只要更新就够了) I call handle it all by myself, expect business matters. (我自己处理所有事情,除了商务事务) I am swamped. (我忙得不可开交) Sentence - email I am here to assist you with anything you need. (我在这里协助你处理任何你需要的事情) I am writing to inform you that… (我写信是为了通知你…) Please let me know if you have any qu...
每天进步一点点 - 基础技术篇
[原创]这篇只是做点记录备忘,个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Make-A-Little-Progress-Every-Day/Make-A-Little-Progress-Every-Day-Basic-Technology.html 本文不怎么更新了 2022-10-25 目前本地缓存使用的方式 订运单系统: SF自研的类Ehcache框架,存储的内容不是特别多,都是一些网点月结卡号信息,所有对象存在于Map,占200m左右 SISP系统: 使用了Caffeine,存储的内容,存储的内容很多,包括员工表(900m),人员表(bdus 800m) 客户表(1.2g),用户及权限相关表(500m) 关联后约占4g内存,目前采用Caffeine默认存储方式,启动即全量加载(极个别采用懒加载方式加载),全部存在于Map中,即堆存储 优化: 缓存为基础数据,数据量稳定,目前采用CMS回收器,堆空间8g,缓存存于堆中,占约4g,平时MajorGC达4~6s,曾出现高峰gc达52s, 应考虑将缓存存于堆外...
性能优化核心思想
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/idea/performance-optimization-core-ideas.html 性能优化核心思想 1. 网络传输上 选择合适的传输协议,如Http->dubbo,以二进制传输+长连接请求 开启序列化、压缩等,对于大数据量的传输可能有特别大的提升 对于重复请求同一个url的连接池,使用长连接 对于不需立即响应的,使用异步请求 对即时聊天等双向实时性要求高的,使用webSocket全双工等 2. JVM 选择合适的GC算法,如CMS、Parallel、G1等 CMS(JDK<1.9)关注低停顿,Parallel关注吞吐量,G1通过较精准把控停顿时间,也可以说是关注整体吞吐量和延迟吧,当前市场上主要用于大内存场景 选择合适的GC参数,如堆内存大小、新生代大小、老年代大小、GC线程数、GC触发条件等 这个属于调优方面的了,需要结合jstat命令与gc detail或者监控工具等配置; 3. 系统架构上的优化(核心) 合理模块依赖关系,...
精准定时任务设计思路
type: drafts [原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/precise-timing-task-design.html 这里主要是以订单超时取消为例 粗略记录,日后完善 取消任务先加入数据库(持久化存储),后加入当前节点时间轮(本地内存) 通过时间轮任务,触发订单取消逻辑、同时把数据库的任务删除 节点重启后,先通过数据库加载属于自己节点的任务到本地时间轮 注意,此处存在一些已经超时的任务,需要加载的时候顺便执行取消订单逻辑,把过期的任务从数据库删除 节点的时间轮恢复,后续继续通过1. 2. 步骤继续运行
支付宝支付流程
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/SA/Study/Alipay-Payment-Process-Analysis.html
关于上游同一数据大批量重复推送问题处理
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/same-data-push.html 先粗略写,日后有缘完善 背景 上游系统在推送数据到下游系统时,由于网络、代码、又或者是运维上(主要是sql重推没去重之类的),导致上游短时间推送大量同一单号给到OMS系统,导致数据库压力剧增 解决方案 新增字段,Version,接收上游数据时先判断Version是否比OMS的大,如果大则更新,否则不更新 Other More 为什么不只用数据库锁版本号或者锁版本号? 先确认概念: Version(数据版本号,解决的是数据新旧问题): version字段用于判断数据版本的新旧。在某些业务场景下,需要检查数据是否被其他操作修改过,以避免数据冲突或脏读的问题。通过比较version字段的值,可以判断当前数据是否是最新版本,如果版本不匹配,则可能意味着数据已被其他操作修改,需要采取相应的处理措施(如回滚、重新读取等)。 lockVersion(乐观锁锁版本号,解决数据并发更新问题): lockVersion...
缓存强一致性方案
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/cache-consistency-solution.html 背景 考虑到部分场景可能需要强一致性缓存: 后端更新时,需要保证使用端查询缓存时立马就能查询出最新的缓存值,且需要考虑并发场景导致的不一致情况 所谓的『强一致性』问题确认 首先,确认的是,我们讨论的一致性问题不是最终一致性这种,而是强一致性,前者可以通过数据库消费binlog设置缓存的形式实现,后者则需要考虑并发场景下的问题 方案设计–基于类似分布式锁实现 在后端更新数据库前,先将缓存值设置为『LOCK』,并设置一个过期时间,这个过期时间需要根据业务场景来设置,一般来说,这个过期时间需要大于后端更新缓存的时间,这样可以保证在后端更新缓存时,缓存值一直是『LOCK』状态 后端更新数据库、提交事务后,再将缓存值设置为『正常值』,这样就可以保证缓存值一直是『LOCK』状态 用户侧使用缓存前时先判断缓存值不为『LOCK』,为『LOCK』则阻塞等待更新完成,否则直接使用缓存值 至此,就可以保证缓存的...
如何提高服务可用性
如何提高服务可用性 [原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/system/how-to-improve-service-availability.html 低层次的说,大概有如下方法 容灾(lvs+keepalived等) 负载均衡+心跳 限流 熔断&降级 重试 业务重试 框架切换节点重试等 监控+预警 业务上下游流量监控+接口流量监控 JVM等指标监控 指定日志监控 主动发送预警 (补充)解耦:动静分离/前后分离 归纳一下针对服务本身,其实也就4种类情况 单点故障 服务响应慢 服务超出自身的承载能力 故障发现与恢复? 1. 单点故障 解决单点故障的其实比较『简单』,就是把单点给去掉,进行一定的『冗余+故障转移』处理。。。 比如把单点的服务部署多份,然后通过负载策略来分发请求,这样就可以避免单点故障了; (当然其实再怎么避免,最靠近用户侧的地方都会有个单点的,我们不讨论这种情况 没啥意义) 设备冗余(跨机房、多机房冗余) 应用冗余(集群化部署) 数据冗余(主从、多主、分片、缓存)...
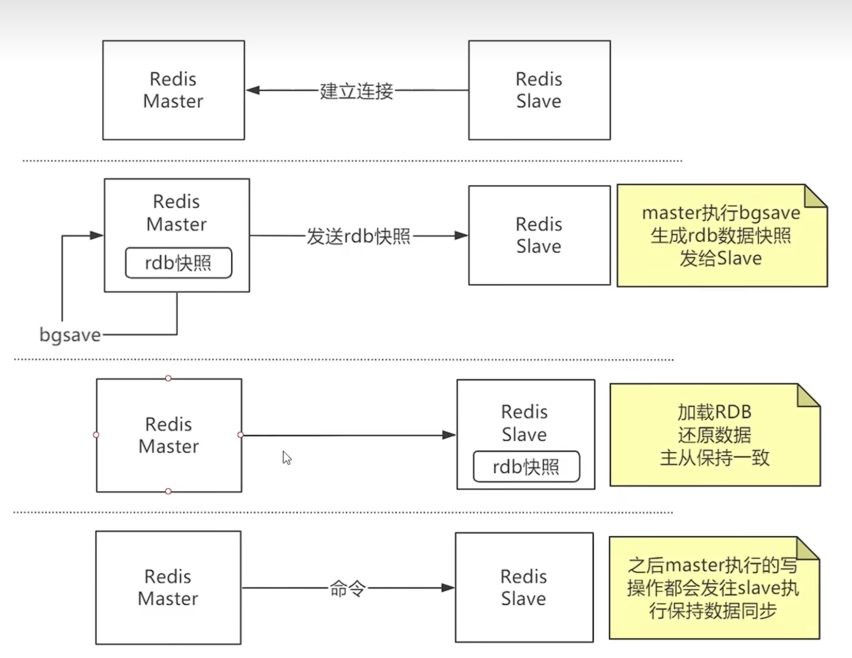
Redis-Sentinel总结
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/redis/Redis-Sentinel-Summary.html 1.Redis主从架构 主节点负责写入操作 从节点可以提供读取操作(可配置,有延迟,高一致性的场景下需要注意) 2.Redis主从复制流程 Redis Slave 与Master建立连接 Master执行bgsave生成rdb快照文件 Master发送rdb快照文件给到Slave Slave接收到rdb快照文件后,清空自己的数据,然后加载rdb快照文件 同时,Master会继续将新的写操作同步给Slave(这里用了老版本用的环形结构,高并发情况下可能会丢数据,新版本用的无盘复制不会有这个问题) Slave加载完rdb快照文件后,开始接收Master的写操作,完成同步 之后Slave会周期性的向Master发送sync命令,Master接收到sync命令后,会将新的写操作同步给Slave,保证数据的一致性 3.Redis-Sentinel高可用集群 每个Sentinel节点每秒钟会向所有Re...
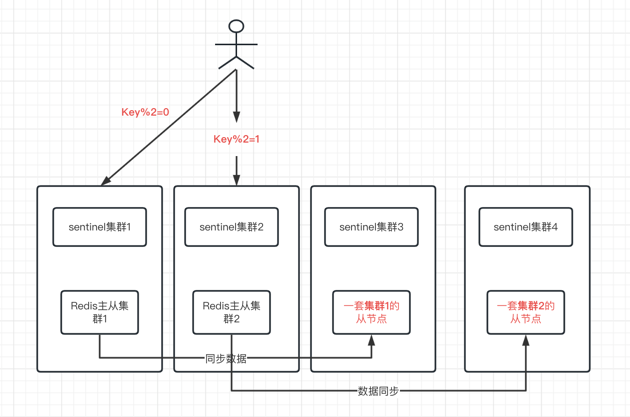
顺丰Redis-Sentinel架构部署
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/sf-redis-sentinel-design.html 接: Redis-Sentinel总结 背景 介于Redis-Sentinel的高可用性,我们在顺丰内部的Redis集群中,大量使用了Redis-Sentinel来保证Redis的高可用性 但是由于Redis主从的复制是异步的,从节点数据略微落后于主节点数据,为了业务的一致性,一般从节点是闲置的,也就是说不会做读写分离 但这种情况下,Redis的最高吞吐量会被限制死在单机的吞吐量上,这对于一些高吞吐量的业务来说,是不够的。 因此有了下面的架构 大概架构思想 当然没下面这么简单,实际上还有一致性hash分片的概念,这里简化了,一致性hash分片的概念可以参考下面的文章 参考:Jedis之ShardedJedis一致性哈希分析 部署3套Redis-Sentinel集群,每套集群包含3个Sentinel节点,3个Redis节点 用户事先配置好所有的Redis-Sentinel节点; 用户连接上Redi...
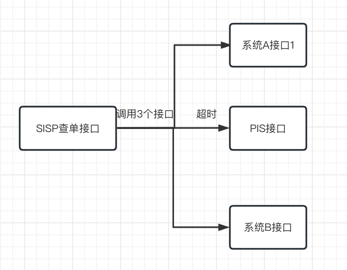
Hystrix熔断优化
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/Hystrix-optimization.html 简述 本文说的其实就是 合理配置熔断,防止依赖的第三方接口响应过慢导致系统tomcat链接大量阻塞,最终导致系统崩溃的问题 顺便,将熔断配置从配置文件中提取出来,动态配置中心中,这样就可以通过动态配置中心来动态配置熔断参数了 除此,主要是团队里大家对单线程并发数与QPS概念有些混淆且计算方式了解不多,以及信号量与线程池方案选择上有些歧义,需要花了不少时间在会议上让团队达成一致。 背景&分析问题 SISP客服系统、SISP查单系统等系统提供的服务都通过HTTP依赖于大量外部各种接口的响应, 这些接口的响应时间不可控,有时候会出现响应时间过长的情况,这时候如果不做任何处理,那么这些请求就会一直等待,这样就会导致系统的响应时间过长,甚至出现系统崩溃的情况。 双十一期间,SISP客服系统出现了系统崩溃问题,经排查发现tomcat线程池被耗尽,进一步排查是因为所依赖的PIS接口响应慢了 简单来说问题大概长...
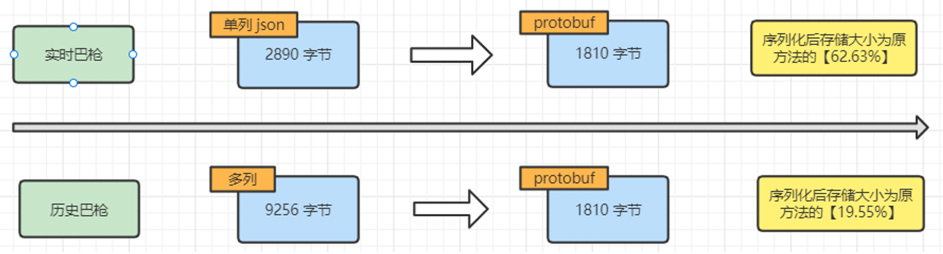
【Hbase优化_2】Hbase存储优化:Hbase数据压缩
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/hbase-data-compress.html 背景 接: 【Hbase优化_1】HBase 行键设计优化:解决数据倾斜问题 随着业务扩张,Hbase使用率越来越高,大数据那边反馈已经没有资源了,全公司都没有了,要扩资源得等公司出去采购,可以的话问我们能否看能不能优化一下Hbase存储,减少一下空间占用。 基于SISP巴枪数据使用业务场景,每行数据是整体从HBase中查询出来,不存在通过字段过滤查询数据、以及只查询某些字段的使用场景,都是将整条数据拿出来、或者整个运单的所有巴枪数据拿出来解析 方案 在可以放弃根据字段过滤的前提下,可以整行巴枪数据序列化存储到HBase。在查询数据时,再将数据做反序列化。序列化可以大幅减少空间占用。以下数据基于本地测试,使用 protobuf 方式进行序列化. 同时,对于历史数据集群,因为其存储为多列数据,因为不需要根据字段过滤,把字段合并为一列,减少列数,也进一步减少空间占用。 预计效果 基于当前实时和历史两个...
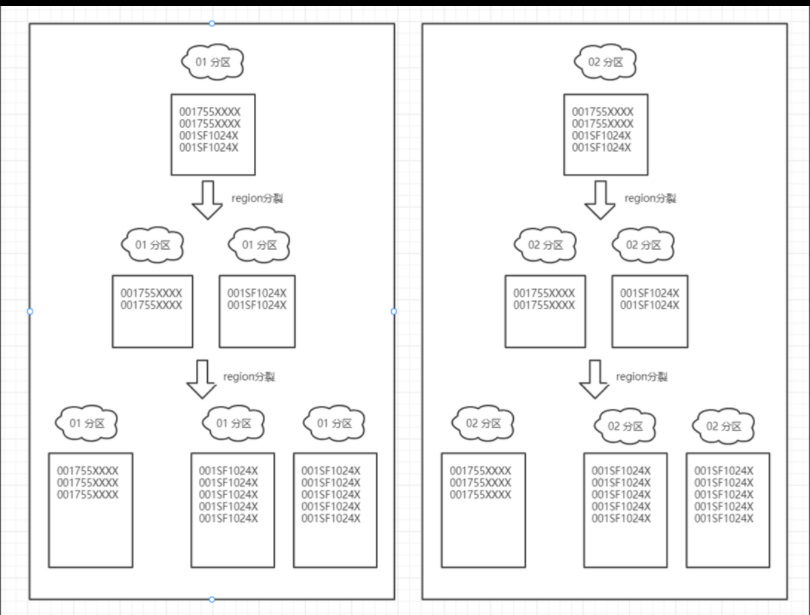
【Hbase优化_1】HBase 行键设计优化:解决数据倾斜问题
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/hbase-region-data-skew.html 这次分享/记录如何通过优化行键设计来解决 HBase 中的数据倾斜问题 在大数据场景下,我们的系统使用 HBase 存储了大量的巴枪信息。其中巴枪信息分布在两个表中,分别是巴枪索引表和巴枪主表。 生产中经常会出现Hbase超时问题,用户也经常反馈原始路由查询、巴枪扫描数据导出等功能查询时间过长、超时等问题。经过分析,发现这些问题的根本原因是 HBase 数据倾斜问题。 1. 巴枪信息表结构 1.1 巴枪索引表 表结构 rowKey: [3位0~499分区号][5位网点编码]|[4位巴枪码]|[操作14位时间字符串]|操作号 value: 巴枪主表的rowkey 示例 rowKey: 2700755W|0030|202204060000129|031801088694 1.2 巴枪主表 表结构 rowKey: [3位0~499分区号][12位运单号]|[4位巴枪码]|[14...
跨域请求减少一半请求
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/web/Reduce-half-of-the-cross-domain-requests.html 简述 点很小,作用挺大,简单写写 客服系统重构后,前端对应的后端服务域名不在同一个(这里没有用nginx解决跨域问题),每次请求都会发送两次请求,一次是预检请求,一次是正式请求。 这样就会导致请求的次数增加一倍,这样就会影响到用户的体验,尤其是对网络不好、国外的用户访问体验带来沉重的打机,新版客服系统上线后叫苦连连。 解决方案 这个问题困扰了好些日子,前些天突然查到一个配置可以很很简单快捷的解决这个问题,这个配置是Access-Control-Max-Age 原理: 后端返回的Access-Control-Max-Age 大于浏览器支持的最大值 那么取浏览器最大值作为缓存时间 否则取后端返回的Access-Control-Max-Age作为缓存时间 缓存时间内不会再发option请求 点这源码 配置 后端对CorsConfiguration配置Access-Contr...
(零拷贝)优化转发型文件下载
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/zero-copy-file-download.html 背景 现有报表系统异步导出报表,生成的报表会上传到对象存储中,因为安全问题,用户不能直接上对象存储系统中下载文件,需要通过报表服务代劳,因为不需要对其做修改,只需做转发,所以这里考虑使用零拷贝技术进行优化 现有做法 把文件数据『下载』下来,然后把对应的文件返回给客户端 数据经过两次拷贝,一次是从对象存储下载到报表服务,一次是从报表服务下载到客户端 12345678910111213141516@Controllerpublic class DownloadController { @RequestMapping(value = "/download", method = RequestMethod.GET) public ResponseEntity<byte[]> downloadFile() throws IOException {...