一文了解ES工作原理
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/%E5%A4%A7%E6%95%B0%E6%8D%AE/ES-work-principle.html
本篇主要针对ES以下内容进行分析
- 写过程
- 读过程
- 读过程-索引原理
- 倒排索引
- es为什么快
以下后续有缘补充
5. 写入数据时的底层数据
6. 更新/删除数据时的底层数据
1. 写过程
客户端请求es,es根据请求的document通过一致性hash算法,找到对应的shard,然后将数据写入到对应的shard中,写入所有主从shard分片成功后,返回客户端。
- 客户端选择一个es-node并把请求发送出去,该节点作为『
协调节点』- 协调节点根据document的id通过一致性hash算法,找到对应的shard,将『
请求转发』给到对应的primary shard对应的node,写入到该shard中- 实际的node接收请求后,将数据写入到对应的primary shard中,然后将数据同步到对应的replica shard中
- 当primary shard和replica shard都写入成功后,『
协调节点』返回响应结果给到客户端
2. 读过程(整体大致过程)
客户端请求es,es根据请求的docId进行hash,判断去哪个shard查询,通过负载查询后,响应g给到客户端
- (同写过程)客户端选择一个es-node并把请求发送出去,该节点作为『
协调节点』- 『
协调节点』根据doc id计算hash,确定所在的shard分片,然后通过随机轮询算法,在primary或者replica shard中选择一个node,将请求转发给到该node- 实际的node接收请求后,将数据从对应的shard中查询出来,然后返回给到『
协调节点』- 『
协调节点』将数据返回给到客户端(★这里在下一段数据检索原理继续细说★)
3. 读过程-数据检索原理(其中细节点)
一般来说,es查询需求会涉及到多个share查询,故需要将多个shard的数据进行合并,然后返回给到客户端,这个过程就是这里说的索引原理
- 各shard返回docid:每个shard分片把自己查询到的结果对应的docid返回给『
协调节点』- 整合docid:『
协调节点』进行数据的合并、排序、分页等操作,然后确定最后需要的数据内容- 根据docid拉取完整数据:『
协调节点』根据手上所需的docid去各个shard分片上拉取实际的document数据- 返回数据:『
协调节点』将拉取到的数据,返回给到客户端
4. 倒排索引
倒排索引是ES的核心,也是ES快的原因之一,倒排索引的核心是将文档中的每个词都建立一个索引,然后指向包含该词的文档,这样就可以快速的定位到文档,从而快速的查询到文档
引用网图:
对于一般的字符串存储在mysql是这样的,我们查询的时候需要逐条查询逐条like匹配,全文检索,效率很低
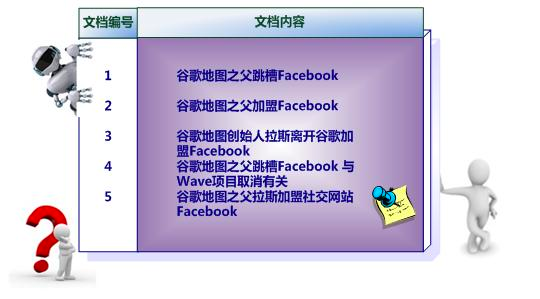
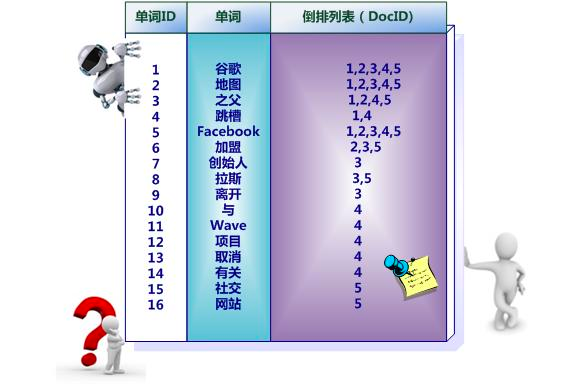
而对于ES,他对每一个可分词字段都有自己的倒排索引,它的倒排索引是这样的,我们查询的时候只需要查询倒排索引,就可以快速的定位到文档,从而快速的查询到文档
PS:其倒排索引
有序,内部根据二分查找法高效定位到查询关键词,快速找到对应的匹配行
5. es为什么快
- 分布式架构:数据存储在多个分片上,并行读写、且可高效水平扩展
- 有序倒排索引:对字段分词的有序的倒排索引,可以快速检索到文档
- 缓存机制:es有自己的缓存机制,可以缓存热点数据,提高查询效率
- 暂时想到这么多,学浅言少