
精准定时任务设计思路
type: drafts
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/precise-timing-task-design.html
这里主要是以订单超时取消为例
粗略记录,日后完善
- 取消任务先加入数据库(持久化存储),后加入当前节点时间轮(本地内存)
- 通过时间轮任务,触发订单取消逻辑、同时把数据库的任务删除
- 节点重启后,先通过数据库加载属于自己节点的任务到本地时间轮
注意,此处存在一些已经超时的任务,需要加载的时候顺便执行取消订单逻辑,把过期的任务从数据库删除 - 节点的时间轮恢复,后续继续通过1. 2. 步骤继续运行
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 花火笔记!
相关推荐
2022-12-02
顺丰Redis-Sentinel架构部署
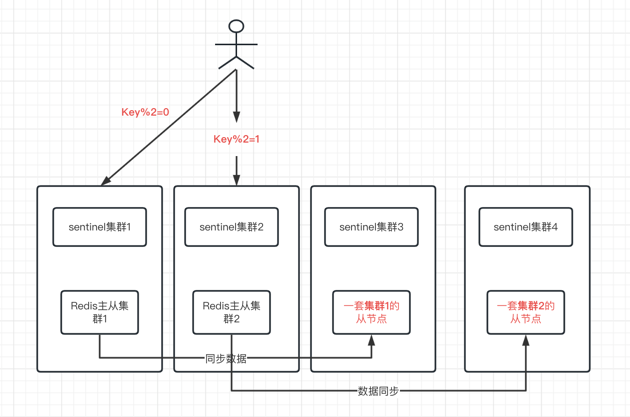
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/sf-redis-sentinel-design.html 接: Redis-Sentinel总结 背景 介于Redis-Sentinel的高可用性,我们在顺丰内部的Redis集群中,大量使用了Redis-Sentinel来保证Redis的高可用性 但是由于Redis主从的复制是异步的,从节点数据略微落后于主节点数据,为了业务的一致性,一般从节点是闲置的,也就是说不会做读写分离 但这种情况下,Redis的最高吞吐量会被限制死在单机的吞吐量上,这对于一些高吞吐量的业务来说,是不够的。 因此有了下面的架构 大概架构思想 当然没下面这么简单,实际上还有一致性hash分片的概念,这里简化了,一致性hash分片的概念可以参考下面的文章 参考:Jedis之ShardedJedis一致性哈希分析 部署3套Redis-Sentinel集群,每套集群包含3个Sentinel节点,3个Redis节点 用户事先配置好所有的Redis-Sentinel节点; 用户连接上Redi...
2021-03-25
snappy压缩redis方案可行性验证
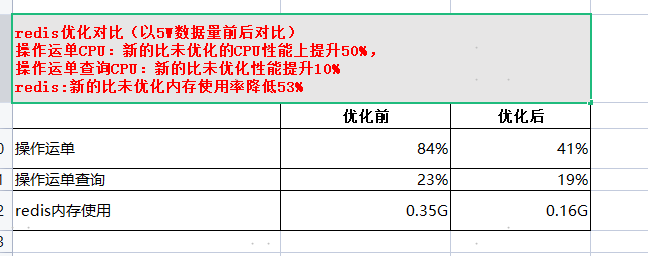
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/snappy-compress-redis.html Snappy压缩方案 研发环境(redis单节点,两个哨兵) 1. 压缩率 压缩前的redis内存: String类型保存1万份不同key,相同value的运单内存为119.61-1.02=118MB: Byte[]类型保存1万份不同key,相同value的运单内存为31.74-1.02=30MB: 结论:改造后的压缩率提升(118-30)/118=74% 2. cpu对比 1. 单线程1万次写入redis String类型,基本维持在5%以下: Byte[]类型,基本维持在5%以下: 结论:cpu对比无明显变化 2. 单线程一万次读取对比: String类型: Byte[]类型: 结论:cpu对比无明显变化 3. 耗时对比 单线程1万次写入redis耗时 单线程1万次读取redi耗时 String类型 135677ms 130027ms byte[]类型 12880...
2023-05-11
关于上游同一数据大批量重复推送问题处理
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/same-data-push.html 先粗略写,日后有缘完善 背景 上游系统在推送数据到下游系统时,由于网络、代码、又或者是运维上(主要是sql重推没去重之类的),导致上游短时间推送大量同一单号给到OMS系统,导致数据库压力剧增 解决方案 新增字段,Version,接收上游数据时先判断Version是否比OMS的大,如果大则更新,否则不更新 Other More 为什么不只用数据库锁版本号或者锁版本号? 先确认概念: Version(数据版本号,解决的是数据新旧问题): version字段用于判断数据版本的新旧。在某些业务场景下,需要检查数据是否被其他操作修改过,以避免数据冲突或脏读的问题。通过比较version字段的值,可以判断当前数据是否是最新版本,如果版本不匹配,则可能意味着数据已被其他操作修改,需要采取相应的处理措施(如回滚、重新读取等)。 lockVersion(乐观锁锁版本号,解决数据并发更新问题): lockVersion...
2022-02-12
业务优化
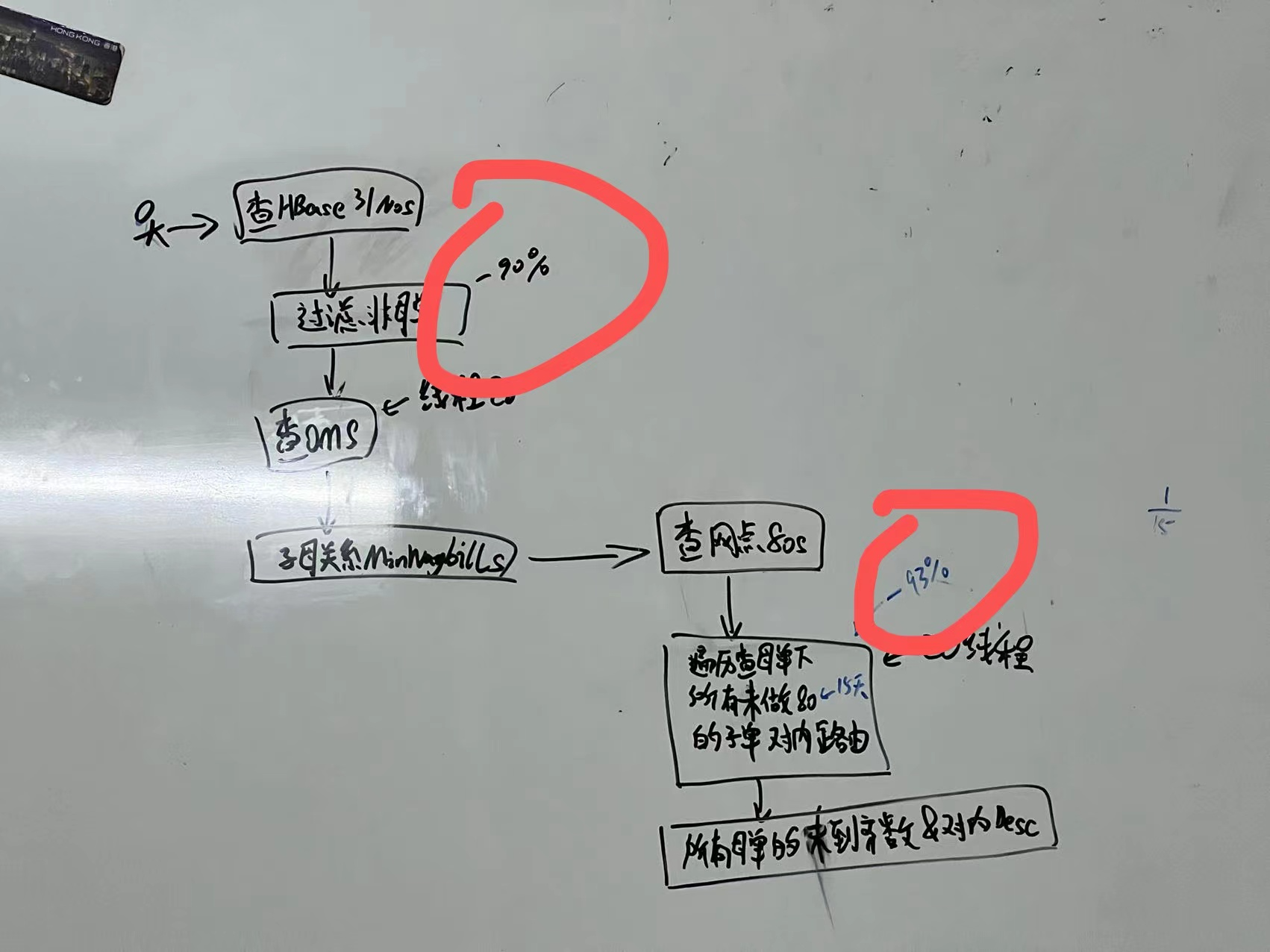
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/business-optimization.html 背景实在太复杂了。。。简单放图,日后完善描述 一个报表需求由不可为,优化到可行并落地:通过多线程以及业务商讨优化,性能优化百倍以上,并满足业务需求。 除了技术手段外关键在于:通过与业务协商,控制查询范围到15天内、删除不必要的字段、筛选数据等各种业务手段减少查询量、http请求量实现。
2022-09-12
【Hbase优化_2】Hbase存储优化:Hbase数据压缩
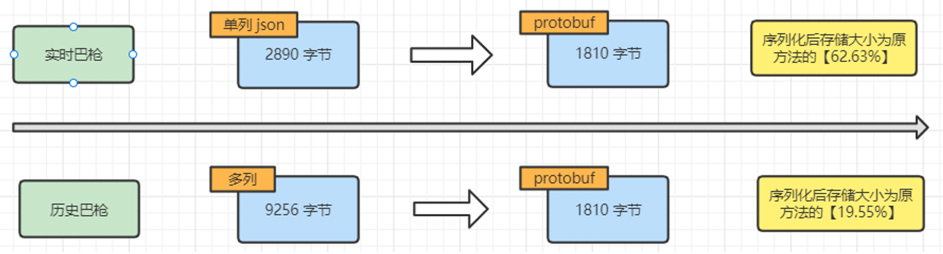
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/hbase-data-compress.html 背景 接: 【Hbase优化_1】HBase 行键设计优化:解决数据倾斜问题 随着业务扩张,Hbase使用率越来越高,大数据那边反馈已经没有资源了,全公司都没有了,要扩资源得等公司出去采购,可以的话问我们能否看能不能优化一下Hbase存储,减少一下空间占用。 基于SISP巴枪数据使用业务场景,每行数据是整体从HBase中查询出来,不存在通过字段过滤查询数据、以及只查询某些字段的使用场景,都是将整条数据拿出来、或者整个运单的所有巴枪数据拿出来解析 方案 在可以放弃根据字段过滤的前提下,可以整行巴枪数据序列化存储到HBase。在查询数据时,再将数据做反序列化。序列化可以大幅减少空间占用。以下数据基于本地测试,使用 protobuf 方式进行序列化. 同时,对于历史数据集群,因为其存储为多列数据,因为不需要根据字段过滤,把字段合并为一列,减少列数,也进一步减少空间占用。 预计效果 基于当前实时和历史两个...
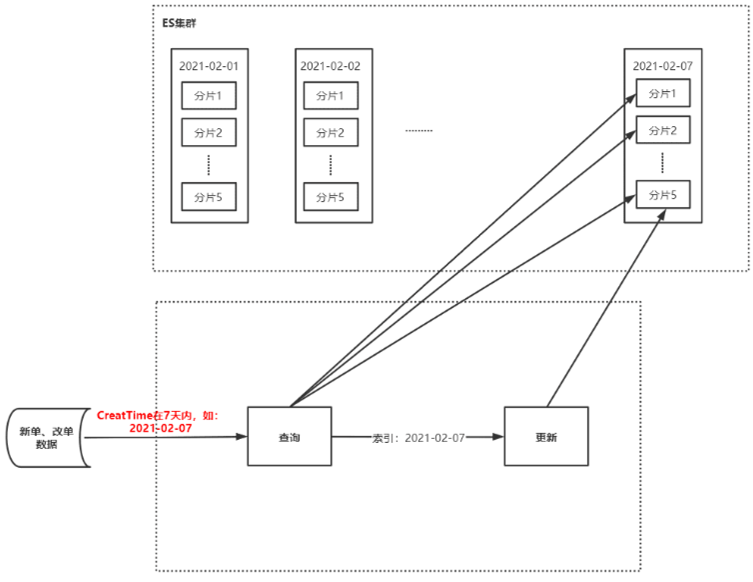
2021-03-02
记一次ES查询优化
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/ES-Query-Optimization.html 背景 难得有数据留存,写一篇^_^ 原逻辑 ES接收新单、改单、状态数据(占总数据的70%),写入ES的7天索引中 ES存在以天为单位的7个索引(如:20210101~20210107,7个索引) 存储逻辑: 根据订单创建时间,保存到对应月日的索引内,如:1月1日的保存到20210101 如果不再最近7天内的特殊订单,那么会存到今天最新的一天的索引内 查询查询: 接收到查单请求后,根据订单创建时间,根据月日指定去查询这7个索引的某一个或多个 如果是在最近7天的,那么保存到该日期对应的索引内 如果在最近7天以外的订单,那么会保存到今天最新的一天的索引内 更新逻辑: 先查询出原来的订单,然后更新,更新后保存到原来的索引内 初步分析 监控问题分析 大数据监控显示:在双十一前后ES监控IO读写次数过高,出现读/写拒绝,CPU占用高,初步分析主要原因有以下: 量大:写入ES的数据...
