
【Hbase优化_2】Hbase存储优化:Hbase数据压缩
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/hbase-data-compress.html
背景
接: 【Hbase优化_1】HBase 行键设计优化:解决数据倾斜问题
随着业务扩张,Hbase使用率越来越高,大数据那边反馈已经没有资源了,全公司都没有了,要扩资源得等公司出去采购,可以的话问我们能否看能不能优化一下Hbase存储,减少一下空间占用。
基于SISP巴枪数据使用业务场景,每行数据是整体从HBase中查询出来,不存在通过字段过滤查询数据、以及只查询某些字段的使用场景,都是将整条数据拿出来、或者整个运单的所有巴枪数据拿出来解析
方案
在可以放弃根据字段过滤的前提下,可以整行巴枪数据序列化存储到HBase。在查询数据时,再将数据做反序列化。序列化可以大幅减少空间占用。以下数据基于本地测试,使用 protobuf 方式进行序列化.
同时,对于历史数据集群,因为其存储为多列数据,因为不需要根据字段过滤,把字段合并为一列,减少列数,也进一步减少空间占用。
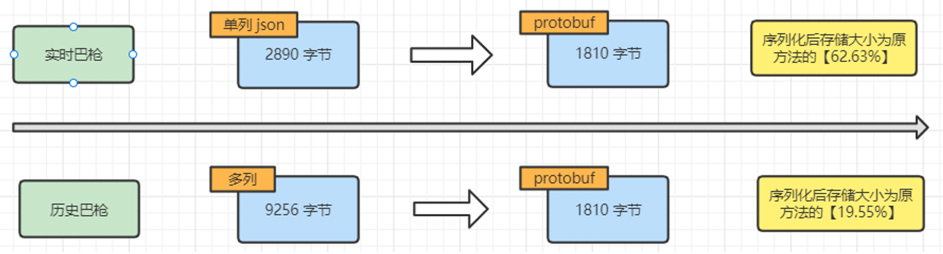
预计效果
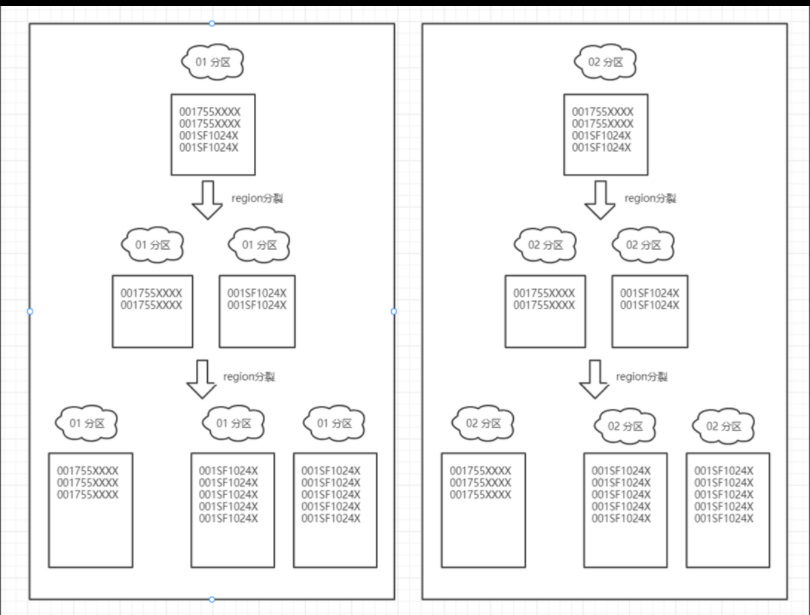
基于当前实时和历史两个HBASE集群占用的空间大小,可以大致计算出序列化后所需要的 region 数量
( 超过10g就算大的region 查询会慢些,region超过20g会自动分裂 。每台机器region不要超过500,超过500就会影响性能。 )
当前集群情况
| 集群 | 当前集群占用 | 当前机器数量 | 当前集群region数量 |
|---|---|---|---|
| 实时数据集群 | 83692GB | 18台 | 20762 |
| 历史数据集群 | 527976GB | 32台 | 24845 |
预计优化后集群情况
| 集群 | 当前集群占用 | 当前机器数量 | 当前集群region数量 |
|---|---|---|---|
| 实时数据集群 | 36825GB(原来的44%) | 18台 | 1800 |
| 历史数据集群 | 58078GB(原来的11%) | 32台 | 2900 |
切换方案
生产上分为实时库与历史库,分别存3+1个月与1年。因为实施方案一样,这里只介绍实时库:
- 上线后3+1个月内读取方式不变,写库时改为新方案双写,以新规则写入新库同时也以旧的规则写入旧库
- 等3+1个月后,读取时只读取新库,写库时只写入新库
- 以上两步做一个开关,一键切换
- 半年后,删除旧库
题外话
这里最后因为使用了数据冗余的兼容过度方案,实际上在过度期间还浪费了不少Hbase资源,好在理论优化幅度确实高,领导们能批hhhh~
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 花火笔记!
相关推荐
2022-08-22
【Hbase优化_1】HBase 行键设计优化:解决数据倾斜问题
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/hbase-region-data-skew.html 这次分享/记录如何通过优化行键设计来解决 HBase 中的数据倾斜问题 在大数据场景下,我们的系统使用 HBase 存储了大量的巴枪信息。其中巴枪信息分布在两个表中,分别是巴枪索引表和巴枪主表。 生产中经常会出现Hbase超时问题,用户也经常反馈原始路由查询、巴枪扫描数据导出等功能查询时间过长、超时等问题。经过分析,发现这些问题的根本原因是 HBase 数据倾斜问题。 1. 巴枪信息表结构 1.1 巴枪索引表 表结构 rowKey: [3位0~499分区号][5位网点编码]|[4位巴枪码]|[操作14位时间字符串]|操作号 value: 巴枪主表的rowkey 示例 rowKey: 2700755W|0030|202204060000129|031801088694 1.2 巴枪主表 表结构 rowKey: [3位0~499分区号][12位运单号]|[4位巴枪码]|[14...
2022-08-02
(零拷贝)优化转发型文件下载
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/zero-copy-file-download.html 背景 现有报表系统异步导出报表,生成的报表会上传到对象存储中,因为安全问题,用户不能直接上对象存储系统中下载文件,需要通过报表服务代劳,因为不需要对其做修改,只需做转发,所以这里考虑使用零拷贝技术进行优化 现有做法 把文件数据『下载』下来,然后把对应的文件返回给客户端 数据经过两次拷贝,一次是从对象存储下载到报表服务,一次是从报表服务下载到客户端 12345678910111213141516@Controllerpublic class DownloadController { @RequestMapping(value = "/download", method = RequestMethod.GET) public ResponseEntity<byte[]> downloadFile() throws IOException {...
2022-09-12
Hystrix熔断优化
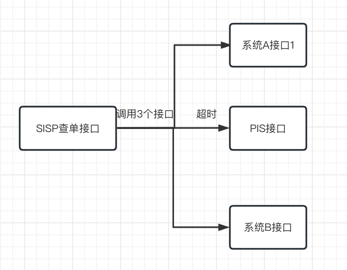
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/Hystrix-optimization.html 简述 本文说的其实就是 合理配置熔断,防止依赖的第三方接口响应过慢导致系统tomcat链接大量阻塞,最终导致系统崩溃的问题 顺便,将熔断配置从配置文件中提取出来,动态配置中心中,这样就可以通过动态配置中心来动态配置熔断参数了 除此,主要是团队里大家对单线程并发数与QPS概念有些混淆且计算方式了解不多,以及信号量与线程池方案选择上有些歧义,需要花了不少时间在会议上让团队达成一致。 背景&分析问题 SISP客服系统、SISP查单系统等系统提供的服务都通过HTTP依赖于大量外部各种接口的响应, 这些接口的响应时间不可控,有时候会出现响应时间过长的情况,这时候如果不做任何处理,那么这些请求就会一直等待,这样就会导致系统的响应时间过长,甚至出现系统崩溃的情况。 双十一期间,SISP客服系统出现了系统崩溃问题,经排查发现tomcat线程池被耗尽,进一步排查是因为所依赖的PIS接口响应慢了 简单来说问题大概长...
2022-02-12
业务优化
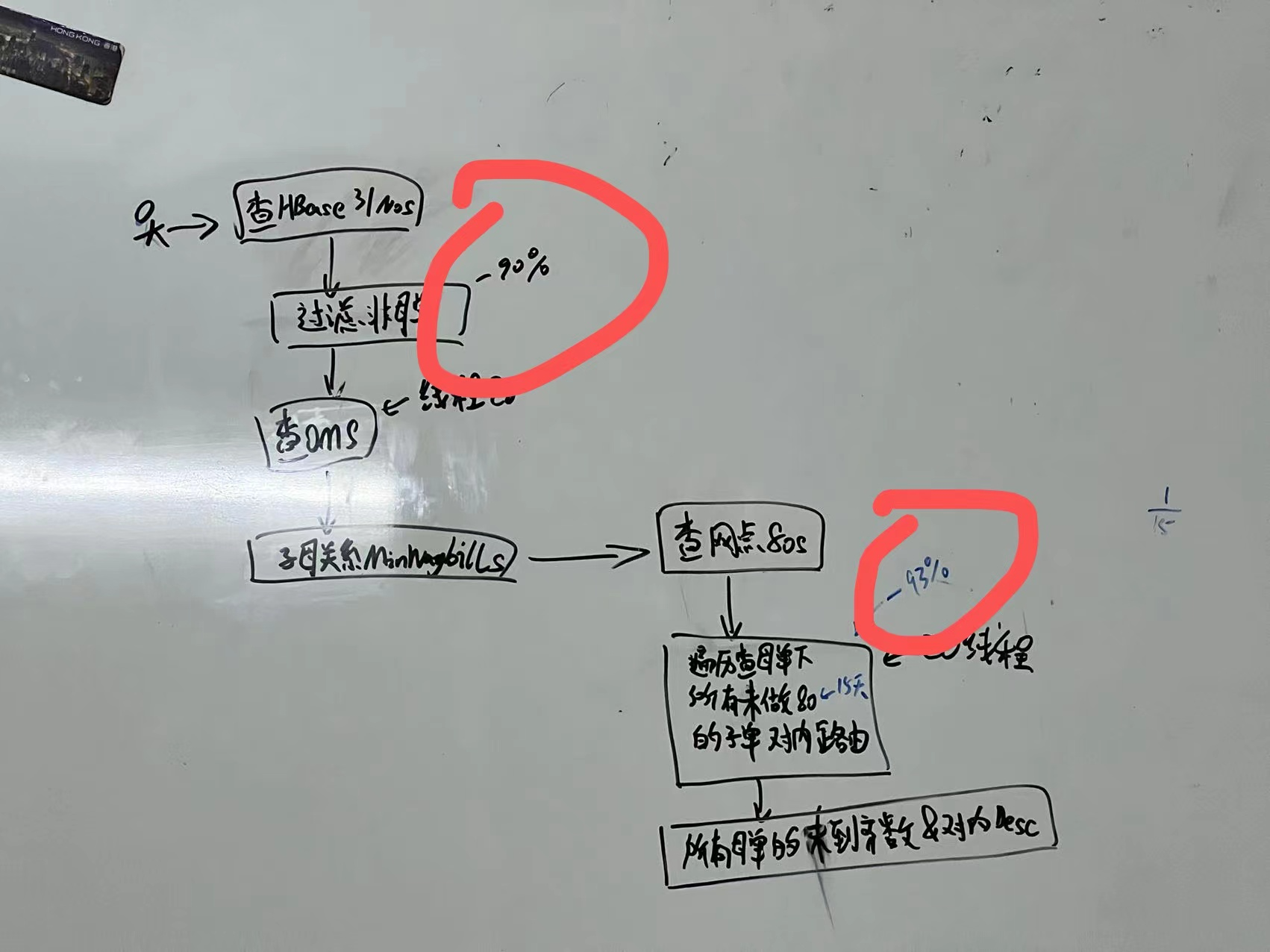
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/business-optimization.html 背景实在太复杂了。。。简单放图,日后完善描述 一个报表需求由不可为,优化到可行并落地:通过多线程以及业务商讨优化,性能优化百倍以上,并满足业务需求。 除了技术手段外关键在于:通过与业务协商,控制查询范围到15天内、删除不必要的字段、筛选数据等各种业务手段减少查询量、http请求量实现。
2021-05-02
生产数据库扩库
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/database-scale.html 背景
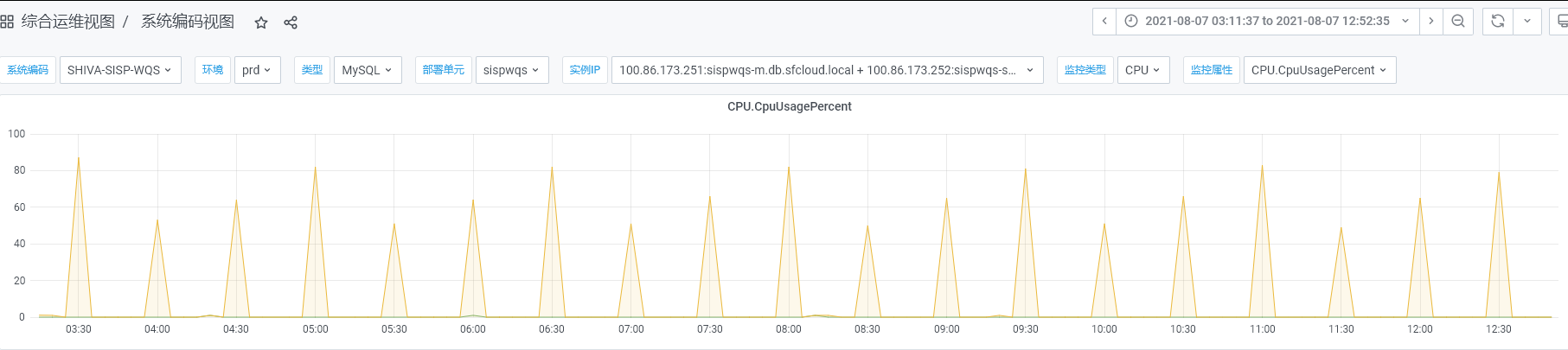
2022-01-04
缓存密集加载导致数据库崩溃问题
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Bug-Log-Optimization/cache-load-database-crash.html 背景 SISP自己基本不存储业务数据,但是每个节点都需要本地缓存了一些网点、员工信息、月结用户信息等基础数据,生产监控发现数据库定期压力飙升,数据库CPU压力到达80+%如图: 用脚趾头分析 从图中可以看出,每天小时飙升一次,明显就是定时任务大批量查询数据库导致的,在SISP系统,也就只有加载缓存可能会导致 找到运维获取慢日志,发现大量的查询语句,如下: 12345SELECT DISTINCT nd.division_code AS city_code, nnd.dist_cn_name , nnd.dist_en_name FROM tm_new_district nd, tm_new_district nnd WHERE nd.division_code IN( SELECT DISTINCT t.CITY_CODE FROM t...
