
【Hbase优化_1】HBase 行键设计优化:解决数据倾斜问题
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/hbase-region-data-skew.html
这次分享/记录如何通过优化行键设计来解决 HBase 中的数据倾斜问题
在大数据场景下,我们的系统使用 HBase 存储了大量的巴枪信息。其中巴枪信息分布在两个表中,分别是巴枪索引表和巴枪主表。
生产中经常会出现Hbase超时问题,用户也经常反馈原始路由查询、巴枪扫描数据导出等功能查询时间过长、超时等问题。经过分析,发现这些问题的根本原因是 HBase 数据倾斜问题。
1. 巴枪信息表结构
1.1 巴枪索引表
表结构
- rowKey: [3位0~499分区号][5位网点编码]|[4位巴枪码]|[操作14位时间字符串]|操作号
- value: 巴枪主表的rowkey
示例
- rowKey: 2700755W|0030|202204060000129|031801088694
1.2 巴枪主表
表结构
- rowKey: [3位0~499分区号][12位运单号]|[4位巴枪码]|[14位时间字符串]|[操作号]
- value: 巴枪数据JSON字符串
示例
- rowKey: 330SF1352340043135|0021|20220404213004|SF1352340043135
2. HBase 数据倾斜问题
由于运单号生成规则问题,运单号的前几位具有很高的相似度。HBase 在数据写入 Region 时,根据 rowKey 进行字符串排序。在 Region 达到阈值分裂后,会出现“数据倾斜”现象,即部分 Region 数据量很大,部分 Region 数据量很小。这会导致大量小 Region 出现,严重消耗 HBase 存储资源、查询资源,同时降低查询效率。
具体点就是:
- Hbase根据分区把数据写入Region后,其数据根据RowKey进行字符串排序,分裂的时候会根据字符串顺序,从大到小切分一半数据到两个Region内,如原Region数据为SF00000-SF99999,切分后可能就是SF00000-SF49999,SF50000-SF99999两个分区
- 因为运单号生成规则问题,前几位相似度很高,因此可见巴枪主表rowKey,除去分区号后,其前几位区分度很低,所以如果hbase Region达到阈值分裂之后,新数据写入会出现『数据倾斜』现象,一些Region很大,一些Region极小,长期写入数据后,会出现大量的小region
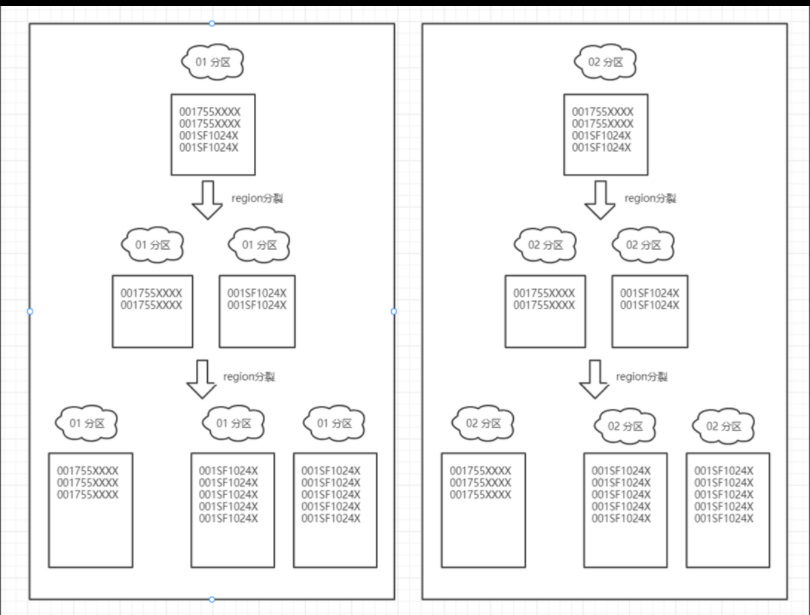
3. 优化方案
3.1 新的巴枪主表 rowKey 规则
新的 rowKey 结构
- rowKey: [3位0~499分区号][运单逆序hash取模3位][先逆序运单号]|[4位巴枪码]|[14位时间字符串]
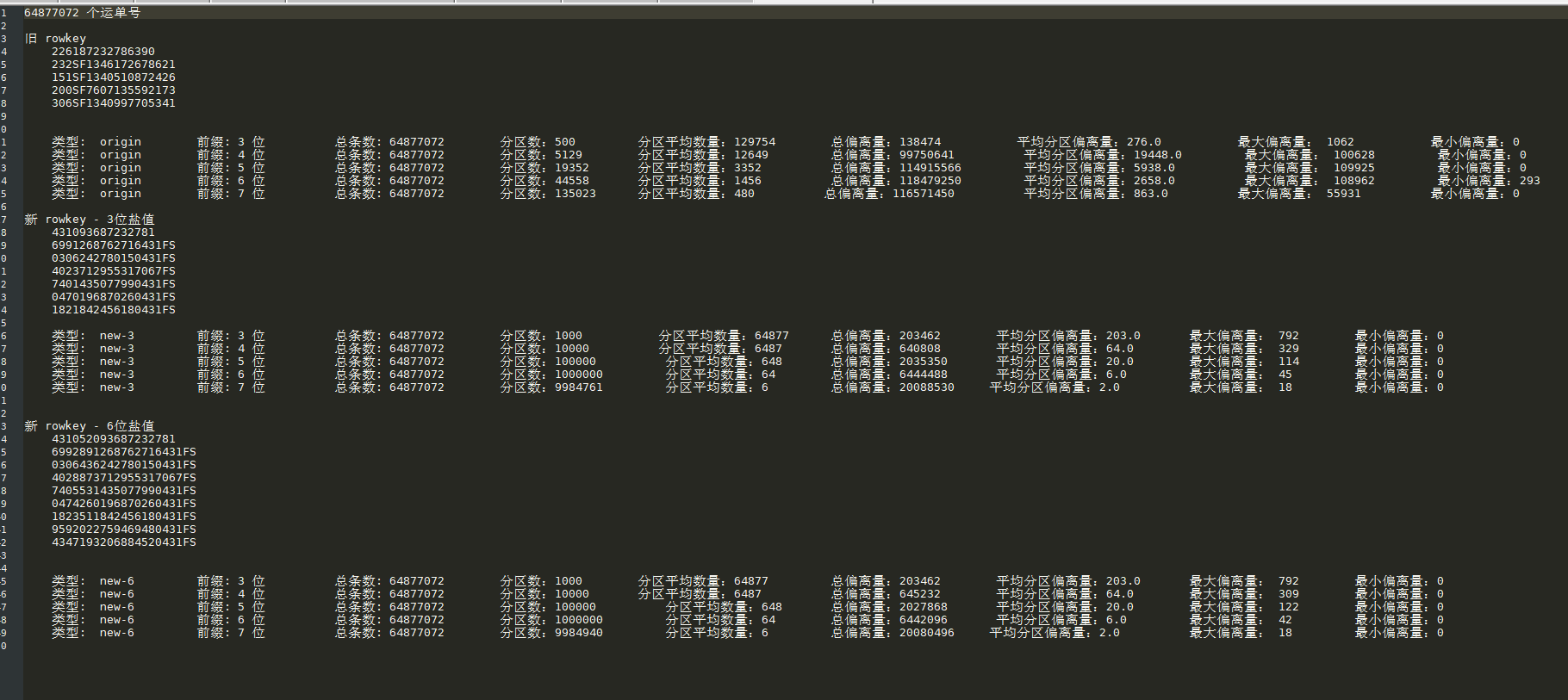
3.2 对比
| 方案 | 总 Region 数量 | 最大 Region 存储数 | 最小 Region 存储数 | 分区量 | 数据倾斜度 |
|---|---|---|---|---|---|
| 现有方案 | 5129 | 113277 | 1 | 多 | 大 |
| 新方案 | 2500 | 26461 | 25380 | 少 | 小 |
结论
新的 rowKey 设计方案可以大幅减少 Region 数量,
数据倾斜度极小,从而有效解决数据倾斜问题。
3.3 生产切换方案
生产上分为实时库与历史库,分别存3+1个月与1年。因为实施方案一样,这里只介绍实时库:
- 上线后3+1个月内读取方式不变,写库时改为新方案双写,以新规则写入新库同时也以旧的规则写入旧库
- 等3+1个月后,读取时只读取新库,写库时只写入新库
- 以上两步做一个开关,一键切换
- 半年后,删除旧库
4. 总结
优化效果因为需要时间沉淀,所以暂无数据对比结果;
通过优化 HBase 行键设计,我们可以解决数据倾斜问题,提高查询效率,降低存储和查询资源消耗。
在实际应用中,根据具体场景和需求,我们需要灵活调整行键设计策略,以实现更高效的数据存储和查询
附录(自己看)
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 花火笔记!
相关推荐
2022-09-12
【Hbase优化_2】Hbase存储优化:Hbase数据压缩
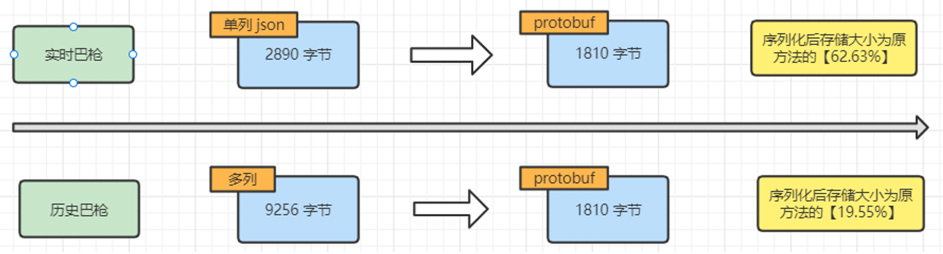
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/hbase-data-compress.html 背景 接: 【Hbase优化_1】HBase 行键设计优化:解决数据倾斜问题 随着业务扩张,Hbase使用率越来越高,大数据那边反馈已经没有资源了,全公司都没有了,要扩资源得等公司出去采购,可以的话问我们能否看能不能优化一下Hbase存储,减少一下空间占用。 基于SISP巴枪数据使用业务场景,每行数据是整体从HBase中查询出来,不存在通过字段过滤查询数据、以及只查询某些字段的使用场景,都是将整条数据拿出来、或者整个运单的所有巴枪数据拿出来解析 方案 在可以放弃根据字段过滤的前提下,可以整行巴枪数据序列化存储到HBase。在查询数据时,再将数据做反序列化。序列化可以大幅减少空间占用。以下数据基于本地测试,使用 protobuf 方式进行序列化. 同时,对于历史数据集群,因为其存储为多列数据,因为不需要根据字段过滤,把字段合并为一列,减少列数,也进一步减少空间占用。 预计效果 基于当前实时和历史两个...
2022-08-02
(零拷贝)优化转发型文件下载
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/zero-copy-file-download.html 背景 现有报表系统异步导出报表,生成的报表会上传到对象存储中,因为安全问题,用户不能直接上对象存储系统中下载文件,需要通过报表服务代劳,因为不需要对其做修改,只需做转发,所以这里考虑使用零拷贝技术进行优化 现有做法 把文件数据『下载』下来,然后把对应的文件返回给客户端 数据经过两次拷贝,一次是从对象存储下载到报表服务,一次是从报表服务下载到客户端 12345678910111213141516@Controllerpublic class DownloadController { @RequestMapping(value = "/download", method = RequestMethod.GET) public ResponseEntity<byte[]> downloadFile() throws IOException {...

2020-08-03
ES文档结构优化
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/es-structure-optimization.html 一个不错的优化: 背景 因为我们对订单的ES索引模板中,orderExtendInfoList存储多个扩展属性,用作外部订单号、二程运单号等信息的存储,业务上需要对其作为条件进行索引,为此我们把他设置为嵌套nested类型。 偶然学习发现这种嵌套nested类型会导致每个订单下的orderExtendInfo都会生成多个文档,导致索引数据量放大几倍,会导致查询性能下降,故重新设计进行优化。 优化ES存储订单数据的结构 把orderExtendInfoList打平并改为keyword类型(原来为嵌套类型), 内部额外存储一个作为索引用的值为原orderExtendInfo的key和value对应的Map 描述起来比较麻烦 大概是把下图左边的变成变成右边的 效果 4亿+数据量减少到只剩下5kw数据量,降低了十倍左右 查询时的CPU与内存压力均降低10%左右
2021-05-02
生产数据库扩库
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/database-scale.html 背景
2021-05-04
数据库数据倾斜
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Bug-Log-Optimization/database-skew.html 其实改动不是很大,这里简单记录下 背景 OMS订单系统,日数据量较大平均近3kw/日,高峰达8kw+/日的订单需要存到数据库中(之前64库,现在扩到了128库); 运维后台监控看到,各个库的压力不一,江浙沪,京津冀,深圳755等地区对应的数据库压力很高,而其他地区的数据库压力很低; 分析 数据库通过mycat,以分库号字段进行分库,以内部订单号分表 内部订单号规则: 3位分库号+系统来源(2位)+MMDDHHmmssSSS+订单类型+6位随机数+1位校验码=26位 分库号生成规则为根据地区、网点进行生成; 因此,可以看出,同一地区的订单,分库号是一样的,因此,同一地区的订单,会落在同一个库中; 解决 直接粗暴修改分库号生成规则为0~127区间随机生成,因为原有订单的删、改、查最终都会带上原有的内部订单号,所以不会影响到历史数据,只是新的订单会落在不同的库中; 上线方案 因为是S级系统...
2022-01-04
缓存密集加载导致数据库崩溃问题
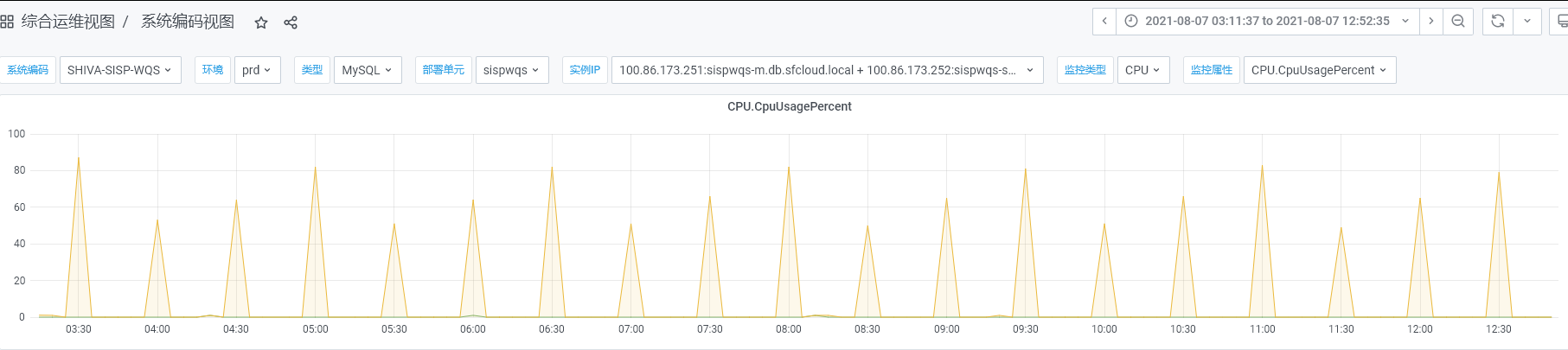
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Bug-Log-Optimization/cache-load-database-crash.html 背景 SISP自己基本不存储业务数据,但是每个节点都需要本地缓存了一些网点、员工信息、月结用户信息等基础数据,生产监控发现数据库定期压力飙升,数据库CPU压力到达80+%如图: 用脚趾头分析 从图中可以看出,每天小时飙升一次,明显就是定时任务大批量查询数据库导致的,在SISP系统,也就只有加载缓存可能会导致 找到运维获取慢日志,发现大量的查询语句,如下: 12345SELECT DISTINCT nd.division_code AS city_code, nnd.dist_cn_name , nnd.dist_en_name FROM tm_new_district nd, tm_new_district nnd WHERE nd.division_code IN( SELECT DISTINCT t.CITY_CODE FROM t...
