
缓存强一致性方案
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/cache-consistency-solution.html
背景
考虑到部分场景可能需要强一致性缓存:
后端更新时,需要保证使用端查询缓存时立马就能查询出最新的缓存值,且需要考虑并发场景导致的不一致情况
所谓的『强一致性』问题确认
首先,确认的是,我们讨论的一致性问题不是最终一致性这种,而是强一致性,前者可以通过数据库消费binlog设置缓存的形式实现,后者则需要考虑并发场景下的问题
方案设计–基于类似分布式锁实现
- 在后端更新数据库前,先将缓存值设置为『LOCK』,并设置一个过期时间,这个过期时间需要根据业务场景来设置,一般来说,这个过期时间需要大于后端更新缓存的时间,这样可以保证在后端更新缓存时,缓存值一直是『LOCK』状态
- 后端更新数据库、提交事务后,再将缓存值设置为『正常值』,这样就可以保证缓存值一直是『LOCK』状态
- 用户侧使用缓存前时先判断缓存值不为『LOCK』,为『LOCK』则阻塞等待更新完成,否则直接使用缓存值
- 至此,就可以保证缓存的强一致性了
可能的问题点
- 缓存频繁更新可能影响读取效率
- redis故障或网络问题导致等缓存更新失败,会导致缓存处于『LOCK』状态一段时间,影响读取效率
结语
- 一般来说,这种场景下,缓存的更新频率不会很高,所以影响不大
- 以上场景在实际业务上其实比较少,更多的还是用延迟双删,或者消费binlog设置缓存实现近实时的最终一致性就行了
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 花火笔记!
相关推荐
2022-12-02
顺丰Redis-Sentinel架构部署
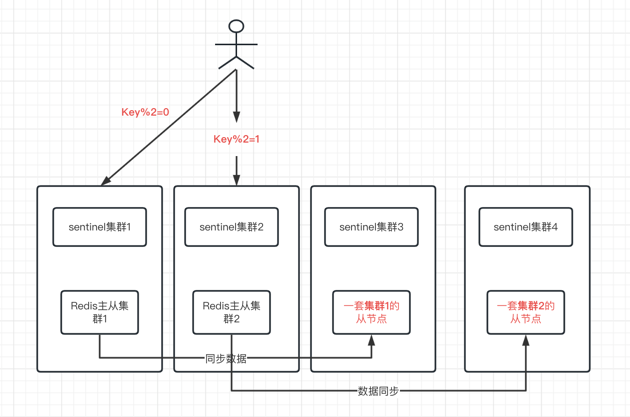
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/sf-redis-sentinel-design.html 接: Redis-Sentinel总结 背景 介于Redis-Sentinel的高可用性,我们在顺丰内部的Redis集群中,大量使用了Redis-Sentinel来保证Redis的高可用性 但是由于Redis主从的复制是异步的,从节点数据略微落后于主节点数据,为了业务的一致性,一般从节点是闲置的,也就是说不会做读写分离 但这种情况下,Redis的最高吞吐量会被限制死在单机的吞吐量上,这对于一些高吞吐量的业务来说,是不够的。 因此有了下面的架构 大概架构思想 当然没下面这么简单,实际上还有一致性hash分片的概念,这里简化了,一致性hash分片的概念可以参考下面的文章 参考:Jedis之ShardedJedis一致性哈希分析 部署3套Redis-Sentinel集群,每套集群包含3个Sentinel节点,3个Redis节点 用户事先配置好所有的Redis-Sentinel节点; 用户连接上Redi...
2022-09-12
Hystrix熔断优化
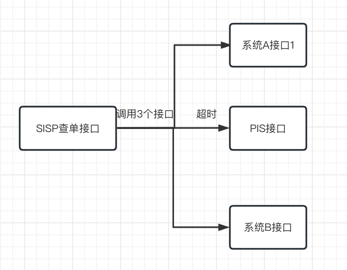
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/Hystrix-optimization.html 简述 本文说的其实就是 合理配置熔断,防止依赖的第三方接口响应过慢导致系统tomcat链接大量阻塞,最终导致系统崩溃的问题 顺便,将熔断配置从配置文件中提取出来,动态配置中心中,这样就可以通过动态配置中心来动态配置熔断参数了 除此,主要是团队里大家对单线程并发数与QPS概念有些混淆且计算方式了解不多,以及信号量与线程池方案选择上有些歧义,需要花了不少时间在会议上让团队达成一致。 背景&分析问题 SISP客服系统、SISP查单系统等系统提供的服务都通过HTTP依赖于大量外部各种接口的响应, 这些接口的响应时间不可控,有时候会出现响应时间过长的情况,这时候如果不做任何处理,那么这些请求就会一直等待,这样就会导致系统的响应时间过长,甚至出现系统崩溃的情况。 双十一期间,SISP客服系统出现了系统崩溃问题,经排查发现tomcat线程池被耗尽,进一步排查是因为所依赖的PIS接口响应慢了 简单来说问题大概长...
2025-12-15
精准定时任务设计思路
type: drafts [原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/precise-timing-task-design.html 这里主要是以订单超时取消为例 粗略记录,日后完善 取消任务先加入数据库(持久化存储),后加入当前节点时间轮(本地内存) 通过时间轮任务,触发订单取消逻辑、同时把数据库的任务删除 节点重启后,先通过数据库加载属于自己节点的任务到本地时间轮 注意,此处存在一些已经超时的任务,需要加载的时候顺便执行取消订单逻辑,把过期的任务从数据库删除 节点的时间轮恢复,后续继续通过1. 2. 步骤继续运行

2019-01-09
MQ常见问题及其处理方案
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/MQ/mq-common-problem.html 基于Rabbitmq:
2021-03-20
Redis压缩方案设计--各种压缩方案单机的比较(CPU)
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/Redis-compress-design.html 1、 CPU性能对比(通过对比CPU时间) 对比论证: 选择序列化CPU使用率最低,约原来的16%~73%,其中FST序列化方式为原来的16%,速度最快 选择纯字符串压缩的方式因为是在原toJSON和parseObject的逻辑之间,再加入压缩逻辑,故性能比原生JSON会略差一些 (对比序列化&压缩方案)每轮十万次测试 压缩方案单轮测试耗时最高,为0.42s,约每次使用该方案消耗0.04ms,对比原方案单次多次0.01ms的CPU时间,故认为以上方案对性能的损耗问题可忽略 序列化方案单论测试耗时最低,为0.05s,约每次使用该方案可节约0.027ms的CPU时间,对比压缩方案,可节约0.037ms的CPU时间,故认为序列化对性能提升不高 总结 纯序列化方案占用CPU时间少,纯压缩方案占用CPU时间稍多,但是都对整体性能影响极小 2、使用序列化实践的方案(速度快,压缩...
2023-05-11
关于上游同一数据大批量重复推送问题处理
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/same-data-push.html 先粗略写,日后有缘完善 背景 上游系统在推送数据到下游系统时,由于网络、代码、又或者是运维上(主要是sql重推没去重之类的),导致上游短时间推送大量同一单号给到OMS系统,导致数据库压力剧增 解决方案 新增字段,Version,接收上游数据时先判断Version是否比OMS的大,如果大则更新,否则不更新 Other More 为什么不只用数据库锁版本号或者锁版本号? 先确认概念: Version(数据版本号,解决的是数据新旧问题): version字段用于判断数据版本的新旧。在某些业务场景下,需要检查数据是否被其他操作修改过,以避免数据冲突或脏读的问题。通过比较version字段的值,可以判断当前数据是否是最新版本,如果版本不匹配,则可能意味着数据已被其他操作修改,需要采取相应的处理措施(如回滚、重新读取等)。 lockVersion(乐观锁锁版本号,解决数据并发更新问题): lockVersion...
