
如何提高服务可用性
如何提高服务可用性
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/system/how-to-improve-service-availability.html
低层次的说,大概有如下方法
- 容灾(lvs+keepalived等)
- 负载均衡+心跳
- 限流
- 熔断&降级
- 重试
- 业务重试
- 框架切换节点重试等
- 监控+预警
- 业务上下游流量监控+接口流量监控
- JVM等指标监控
- 指定日志监控
- 主动发送预警
- (补充)解耦:动静分离/前后分离
归纳一下针对服务本身,其实也就4种类情况
- 单点故障
- 服务响应慢
- 服务超出自身的承载能力
- 故障发现与恢复?
1. 单点故障
解决单点故障的其实比较『简单』,就是把单点给去掉,进行一定的『冗余+故障转移』处理。。。
比如把单点的服务部署多份,然后通过负载策略来分发请求,这样就可以避免单点故障了;
(当然其实再怎么避免,最靠近用户侧的地方都会有个单点的,我们不讨论这种情况 没啥意义)
- 设备冗余(跨机房、多机房冗余)
- 应用冗余(集群化部署)
- 数据冗余(主从、多主、分片、缓存)
2. 服务响应慢
这里抛开代码层面,只考虑架构设计层面,代码层面无非就是减少操作步骤,进行异步处理、并行处理、集中批处理等等。。。算了一起写吧
这里主要需要提高单机的吞吐量,也就是提高单机的性能,这里主要有两种方式:
- 单机吞吐量:
- 多级缓存: 减少非必要更新、查询、调用量
- 代码层面: 就是减少操作步骤,进行异步处理、并行处理、集中批处理等等
- 提高单机的性能: 比如增加CPU、内存、磁盘等等
- 提高集群吞吐量:
- 集群扩容: 增加应用/机器数量
3. 服务超出自身的承载能力
其实这里主要是服务治理相关的问题
- 限流(流量特大的时候一般用代理层限流,应用层一般用hystrix、sentinel等,其中前者为滑动窗口限流,后者基于漏洞实现,前者有流量突刺,后者稳流,个人认为后者应用起来比较贴合实际一些)
- 熔断&降级
4. 故障发现与恢复
- 监控+预警
- 业务上下游流量监控、接口流量监控、P99、接口成功率监控等
- JVM等指标监控
- 指定日志监控
- 主动发送预警
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 花火笔记!
相关推荐
2021-10-03
shell-系统优雅停机
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/system/system-graceful-shutdown.html 脚本 1234567891011#!/bin/bashecho "请输入进程ID:"read pidecho "正在尝试使用kill -15终止进程$pid ..."kill -15 $pidsleep 5 # 等待5秒,给进程清理和资源回收的时间if ps -p $pid > /dev/null; then # 如果进程仍然存在,则使用kill -9进行强制终止 echo "进程$pid 仍在运行,正在尝试使用kill -9强制终止 ..." kill -9 $pidfiecho "进程$pid 已终止"
2020-10-03
IO模型
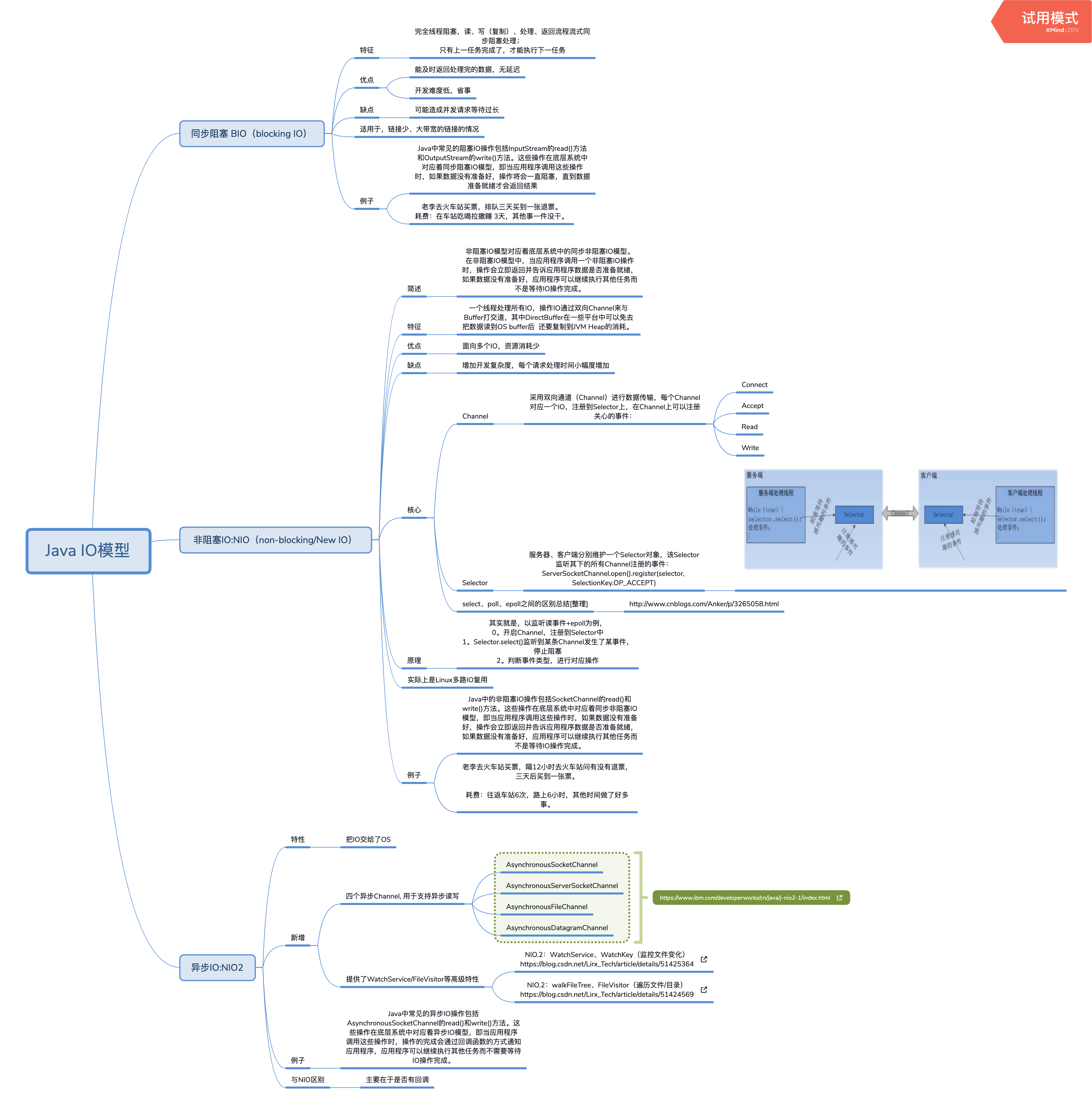
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/system/IO-model.html 背景 服务器网络模型 这篇IO模型是《每天进步一点点》里的第一篇学习记录,真的是忘了看看了忘了。。其实不用记服务器的,大概理一下JAVA自己的就简单多了,这里稍微总结一下: JAVA IO模型 JAVA的IO模型分为BIO、NIO、AIO三种,其中BIO是阻塞IO,NIO是非阻塞IO,AIO是异步IO 阻塞IO模型: Java中常见的阻塞IO操作包括InputStream的read()方法和OutputStream的write()方法。这些操作在底层系统中对应着同步阻塞IO模型,即当应用程序调用这些操作时,如果数据没有准备好,操作将会一直阻塞,直到数据准备就绪才会返回结果。 非阻塞IO模型: Java中的非阻塞IO操作包括SocketChannel的read()和write()方法。这些操作在底层系统中对应着同步非阻塞IO模型,即当应用程序调用这些操作时,如果数据没有准备好,操作会立即返回并告诉应用程序数据是否准备就绪,如果数...
2022-09-12
Hystrix熔断优化
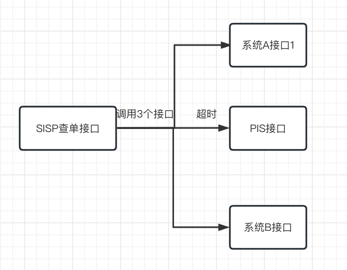
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/Hystrix-optimization.html 简述 本文说的其实就是 合理配置熔断,防止依赖的第三方接口响应过慢导致系统tomcat链接大量阻塞,最终导致系统崩溃的问题 顺便,将熔断配置从配置文件中提取出来,动态配置中心中,这样就可以通过动态配置中心来动态配置熔断参数了 除此,主要是团队里大家对单线程并发数与QPS概念有些混淆且计算方式了解不多,以及信号量与线程池方案选择上有些歧义,需要花了不少时间在会议上让团队达成一致。 背景&分析问题 SISP客服系统、SISP查单系统等系统提供的服务都通过HTTP依赖于大量外部各种接口的响应, 这些接口的响应时间不可控,有时候会出现响应时间过长的情况,这时候如果不做任何处理,那么这些请求就会一直等待,这样就会导致系统的响应时间过长,甚至出现系统崩溃的情况。 双十一期间,SISP客服系统出现了系统崩溃问题,经排查发现tomcat线程池被耗尽,进一步排查是因为所依赖的PIS接口响应慢了 简单来说问题大概长...
2020-10-18
Java I/O模型与系统I/O模型
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/system/IO-model2.html 接: IO模型 Java I/O模型与系统I/O模型的映射关系 Java的I/O模型是建立在底层系统I/O模型之上的,它通过对底层系统I/O调用的封装,提供了更高层次的抽象和统一的I/O接口。Java的I/O类库支持的I/O模型和底层系统I/O模型之间的映射关系如下: 阻塞式I/O模型 Java的I/O类库默认使用阻塞式I/O模型。在该模型下,I/O操作会一直阻塞,直到数据准备好或者操作完成才返回。对应的系统I/O模型是传统的阻塞式I/O模型。主要对应的系统I/O模型是Linux系统中的read(), write() 这里主要是各种Stream、Reader、Writer、Socket的读写,其中Socket为: 1234567891011121314ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();// 监听 8080 端口进来的 TC...
2022-09-12
【Hbase优化_2】Hbase存储优化:Hbase数据压缩
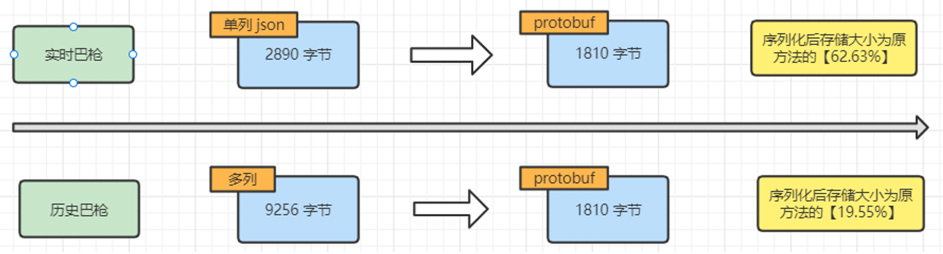
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/hbase-data-compress.html 背景 接: 【Hbase优化_1】HBase 行键设计优化:解决数据倾斜问题 随着业务扩张,Hbase使用率越来越高,大数据那边反馈已经没有资源了,全公司都没有了,要扩资源得等公司出去采购,可以的话问我们能否看能不能优化一下Hbase存储,减少一下空间占用。 基于SISP巴枪数据使用业务场景,每行数据是整体从HBase中查询出来,不存在通过字段过滤查询数据、以及只查询某些字段的使用场景,都是将整条数据拿出来、或者整个运单的所有巴枪数据拿出来解析 方案 在可以放弃根据字段过滤的前提下,可以整行巴枪数据序列化存储到HBase。在查询数据时,再将数据做反序列化。序列化可以大幅减少空间占用。以下数据基于本地测试,使用 protobuf 方式进行序列化. 同时,对于历史数据集群,因为其存储为多列数据,因为不需要根据字段过滤,把字段合并为一列,减少列数,也进一步减少空间占用。 预计效果 基于当前实时和历史两个...
2020-08-12
秒杀架构设计
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/framework-design/sec-kill-framework-design.html 常见的三类高并发场景 高并发压力主要来自,并发时出现大量锁冲突 1.细颗粒度操作-锁冲突少 如:QQ微信等即时通讯业务个人读个人自己的数据 数据结构 个人信息 user(uid…) 几十亿 个人的好友信息 friend(uid,friend_id…) 几百亿 个人的群 user_group(uid,group_id…) 几百亿 群成员 group_member(gid,uid…) 几千亿 个人消息(msg_id,uid…) 几千亿 群消息(msg_id,gid…) 几千亿 个人和群都是读写自己的数据 在高并发时(单个用户单位时间发出N个读写请求),锁冲突极小,每个【人】、【群】、【消息】只会锁住自己部分的消息 在出现IO瓶颈的时候 只需要进行水平分库 把【人】、【群】、【消息】进行切分 2.读多写少,存在少量写冲突 如:微博 自己的...
