
秒杀架构设计
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/framework-design/sec-kill-framework-design.html
常见的三类高并发场景
高并发压力主要来自,并发时出现大量锁冲突
1.细颗粒度操作-锁冲突少 如:QQ微信等即时通讯业务个人读个人自己的数据
数据结构
- 个人信息 user(uid…) 几十亿
- 个人的好友信息 friend(uid,friend_id…) 几百亿
- 个人的群 user_group(uid,group_id…) 几百亿
- 群成员 group_member(gid,uid…) 几千亿
- 个人消息(msg_id,uid…) 几千亿
- 群消息(msg_id,gid…) 几千亿
个人和群都是读写自己的数据
在高并发时(单个用户单位时间发出N个读写请求),锁冲突极小,每个【人】、【群】、【消息】只会锁住自己部分的消息
在出现IO瓶颈的时候 只需要进行水平分库 把【人】、【群】、【消息】进行切分
2.读多写少,存在少量写冲突 如:微博 自己的写为别人的读
拉模式的大概数据结构 参考:微博Feed业务架构–推拉模式
- 个人信息 user (uid…) 几十亿
- 个人的关注列表 user_follow (id,uid,follow_id…) 几百亿
- 个人发出的微博 msg (msg_id,uid…) 几百亿
大概流程:
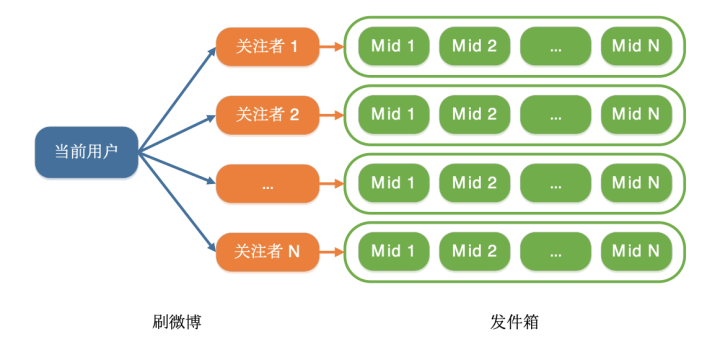
假设用的是拉模式,多个粉丝拉取别的某位用户的发件箱时容易出现读写锁冲突
如: 在某明星粉丝刷微博时,明星消息表、评论表被快速读写,出现锁冲突,宕机
3.(同一份数据)多读多写,存在大量写冲突 如:12306秒杀业务
大概数据结构
- stock(s_id,time) //列车
- ticket(t_id,num,s_id) //列车余票
用户量大,并发很大时, 有极大的锁冲突,极容易把系统搞垮
一辆车几百万请求,有效请求200,成功请求数0,最终请求成功率≈0%
解决【多读多写,存在大量写冲突】的锁冲突问题
主要方向为降低【数据库层面的锁冲突】
(1)降低读请求:利用缓存
(2)降低写请求:上游尽量过滤无效请求
(1)降低读请求:尽可能利用缓存
- 前端: 浏览器、Nginx等静态页面缓存
- 站点层、服务层: 缓存结果、缓存数据…
(2)降低写请求:上游尽量过滤无效请求
- 前端: 通过JS做限速,减少99%请求(如:频繁点击,显示频率过快)
- 站点层: 拦截同个用户的重复请求(通过web层缓存或缓存集群 对[UID+TOKEN]进行计数&限速)
- 服务层: 通过MQ、内存队列收集请求(队列长度根据数据库抗压能力、库存数量设置)
- 数据库层: 单个主从
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 花火笔记!
相关推荐
2020-07-02
微博Feed流读扩散设计
学习自58沈剑← [知识整理]根据个人理解整理后分享,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/Weibo-feed-design.html 什么是Feed流 Feed流即持续更新并呈现给用户内容的信息流 , 对于微博.微信朋友圈等业务刷新的数据都为Feed流 每条微博 朋友圈 为一条Feed 关键动作,关键数据 关键动作 关注 , 取关 发布Feed(朋友圈or微博) 获取自己主页的Feed流 核心数据 关系数据 Feed数据 难点 自己的主页由他人的Feed流组成 如果大家都是读写同一条Feed,会出现较大的读写冲突 造成系统的主要瓶颈 获取Feed流解决方案 模式有2种类: 拉模式 推模式 拉取模式 大致的数据结构 用户关系 用户的关注关系 user_follow(id,uid,follow_id…) 用户的粉丝关系 user_fans(id,uid,fans_id) //之所以要分成正反表是为了大数据量高并发情况下 可以做到分库 用户的消息列表(Feed) 用户...
2021-05-04
数据库数据倾斜
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Bug-Log-Optimization/database-skew.html 其实改动不是很大,这里简单记录下 背景 OMS订单系统,日数据量较大平均近3kw/日,高峰达8kw+/日的订单需要存到数据库中(之前64库,现在扩到了128库); 运维后台监控看到,各个库的压力不一,江浙沪,京津冀,深圳755等地区对应的数据库压力很高,而其他地区的数据库压力很低; 分析 数据库通过mycat,以分库号字段进行分库,以内部订单号分表 内部订单号规则: 3位分库号+系统来源(2位)+MMDDHHmmssSSS+订单类型+6位随机数+1位校验码=26位 分库号生成规则为根据地区、网点进行生成; 因此,可以看出,同一地区的订单,分库号是一样的,因此,同一地区的订单,会落在同一个库中; 解决 直接粗暴修改分库号生成规则为0~127区间随机生成,因为原有订单的删、改、查最终都会带上原有的内部订单号,所以不会影响到历史数据,只是新的订单会落在不同的库中; 上线方案 因为是S级系统...

2020-08-03
ES文档结构优化
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/es-structure-optimization.html 一个不错的优化: 背景 因为我们对订单的ES索引模板中,orderExtendInfoList存储多个扩展属性,用作外部订单号、二程运单号等信息的存储,业务上需要对其作为条件进行索引,为此我们把他设置为嵌套nested类型。 偶然学习发现这种嵌套nested类型会导致每个订单下的orderExtendInfo都会生成多个文档,导致索引数据量放大几倍,会导致查询性能下降,故重新设计进行优化。 优化ES存储订单数据的结构 把orderExtendInfoList打平并改为keyword类型(原来为嵌套类型), 内部额外存储一个作为索引用的值为原orderExtendInfo的key和value对应的Map 描述起来比较麻烦 大概是把下图左边的变成变成右边的 效果 4亿+数据量减少到只剩下5kw数据量,降低了十倍左右 查询时的CPU与内存压力均降低10%左右
2023-04-20
如何提高服务可用性
如何提高服务可用性 [原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/system/how-to-improve-service-availability.html 低层次的说,大概有如下方法 容灾(lvs+keepalived等) 负载均衡+心跳 限流 熔断&降级 重试 业务重试 框架切换节点重试等 监控+预警 业务上下游流量监控+接口流量监控 JVM等指标监控 指定日志监控 主动发送预警 (补充)解耦:动静分离/前后分离 归纳一下针对服务本身,其实也就4种类情况 单点故障 服务响应慢 服务超出自身的承载能力 故障发现与恢复? 1. 单点故障 解决单点故障的其实比较『简单』,就是把单点给去掉,进行一定的『冗余+故障转移』处理。。。 比如把单点的服务部署多份,然后通过负载策略来分发请求,这样就可以避免单点故障了; (当然其实再怎么避免,最靠近用户侧的地方都会有个单点的,我们不讨论这种情况 没啥意义) 设备冗余(跨机房、多机房冗余) 应用冗余(集群化部署) 数据冗余(主从、多主、分片、缓存)...
2019-12-31
Kafka延时队列方案探讨
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/Kafka-Delay-Queue.html 目前在用方案:直接重新丢回队列后面 实现逻辑 引入延迟消息消费服务,消费延迟消息 每条消息消费时,Sleep3秒(很长),再处理; 处理时判断是否到点,没到点的数据丢回kafka 优点 不引入新依赖(不依赖DB,不依赖其他第三方) 缺点 1. 处理效率慢,并发低 2. 延时时间不精准,颗粒度非常大 3. 浪费Kafka空间,同一数据在Kafka多次存储(其实Kafka底层是一种文件/文档存储,消息的消费只读不删) 优化方案1: 延迟消息存DB,通过Redis的zset结构支持 ### 实现逻辑 #### 1. 发送延时消息: > 延时消息发送到延时队列TopicA ### 2. 消费延时消息: > 延时程序(消费者)消费延迟队列的消息,把延时消息存入DB,再把[发送时间]+[延时消息在DB记录ID]作为zset设到Redis ### 3. 监控&&发送[到时的消息]: > 1....
2022-06-12
通用kafka延迟队列生产实践
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/general-kafka-delay-queue.html 接: Kafka延时队列方案探讨
