
数据库数据倾斜
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Bug-Log-Optimization/database-skew.html
其实改动不是很大,这里简单记录下
背景
- OMS订单系统,日数据量较大平均近3kw/日,高峰达8kw+/日的订单需要存到数据库中(之前64库,现在扩到了128库);
- 运维后台监控看到,各个库的压力不一,江浙沪,京津冀,深圳755等地区对应的数据库压力很高,而其他地区的数据库压力很低;
分析
- 数据库通过mycat,以分库号字段进行分库,以内部订单号分表
- 内部订单号规则: 3位分库号+系统来源(2位)+MMDDHHmmssSSS+订单类型+6位随机数+1位校验码=26位
- 分库号生成规则为根据地区、网点进行生成;
因此,可以看出,同一地区的订单,分库号是一样的,因此,同一地区的订单,会落在同一个库中;
解决
直接粗暴修改分库号生成规则为0~127区间随机生成,因为原有订单的删、改、查最终都会带上原有的内部订单号,所以不会影响到历史数据,只是新的订单会落在不同的库中;
上线方案
因为是S级系统,上线加了开关,如若有问题,可以快速回滚,因为是中台消费者系统,期间如果出问题的数据通过关闭开关+kfk重置偏移量解决。
上线后效果
(此处应有截图)
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 花火笔记!
相关推荐
2021-03-02
记一次ES查询优化
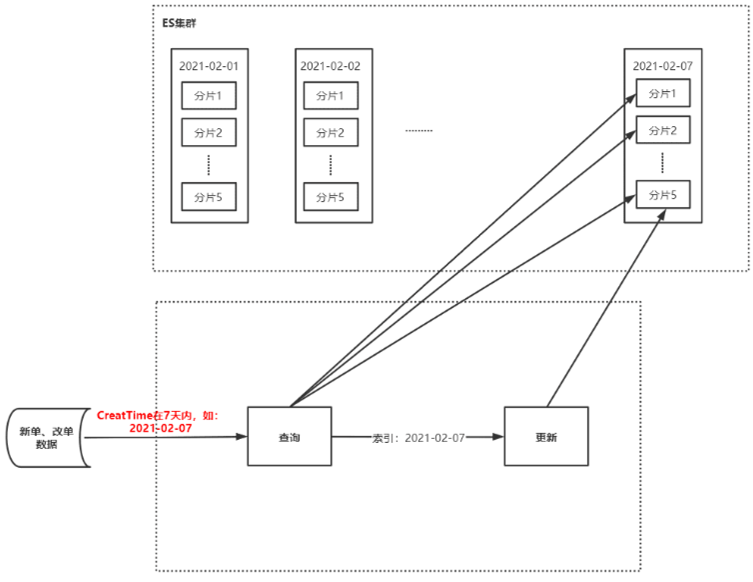
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/ES-Query-Optimization.html 背景 难得有数据留存,写一篇^_^ 原逻辑 ES接收新单、改单、状态数据(占总数据的70%),写入ES的7天索引中 ES存在以天为单位的7个索引(如:20210101~20210107,7个索引) 存储逻辑: 根据订单创建时间,保存到对应月日的索引内,如:1月1日的保存到20210101 如果不再最近7天内的特殊订单,那么会存到今天最新的一天的索引内 查询查询: 接收到查单请求后,根据订单创建时间,根据月日指定去查询这7个索引的某一个或多个 如果是在最近7天的,那么保存到该日期对应的索引内 如果在最近7天以外的订单,那么会保存到今天最新的一天的索引内 更新逻辑: 先查询出原来的订单,然后更新,更新后保存到原来的索引内 初步分析 监控问题分析 大数据监控显示:在双十一前后ES监控IO读写次数过高,出现读/写拒绝,CPU占用高,初步分析主要原因有以下: 量大:写入ES的数据...
2022-01-04
缓存密集加载导致数据库崩溃问题
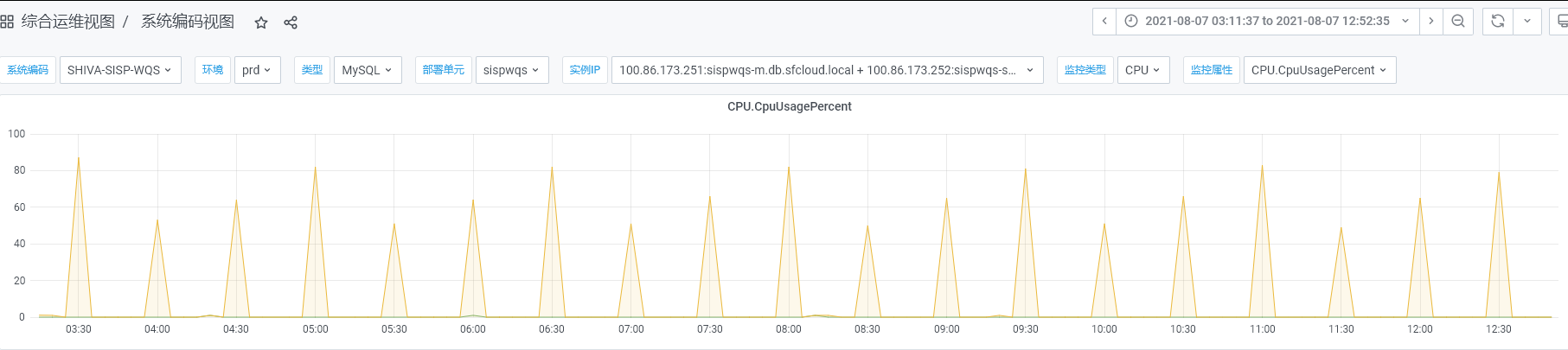
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Bug-Log-Optimization/cache-load-database-crash.html 背景 SISP自己基本不存储业务数据,但是每个节点都需要本地缓存了一些网点、员工信息、月结用户信息等基础数据,生产监控发现数据库定期压力飙升,数据库CPU压力到达80+%如图: 用脚趾头分析 从图中可以看出,每天小时飙升一次,明显就是定时任务大批量查询数据库导致的,在SISP系统,也就只有加载缓存可能会导致 找到运维获取慢日志,发现大量的查询语句,如下: 12345SELECT DISTINCT nd.division_code AS city_code, nnd.dist_cn_name , nnd.dist_en_name FROM tm_new_district nd, tm_new_district nnd WHERE nd.division_code IN( SELECT DISTINCT t.CITY_CODE FROM t...
2022-09-12
Hystrix熔断优化
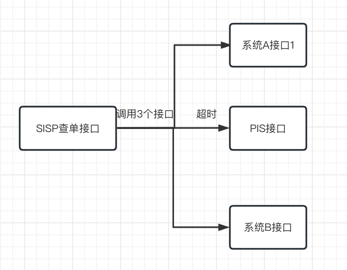
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/Hystrix-optimization.html 简述 本文说的其实就是 合理配置熔断,防止依赖的第三方接口响应过慢导致系统tomcat链接大量阻塞,最终导致系统崩溃的问题 顺便,将熔断配置从配置文件中提取出来,动态配置中心中,这样就可以通过动态配置中心来动态配置熔断参数了 除此,主要是团队里大家对单线程并发数与QPS概念有些混淆且计算方式了解不多,以及信号量与线程池方案选择上有些歧义,需要花了不少时间在会议上让团队达成一致。 背景&分析问题 SISP客服系统、SISP查单系统等系统提供的服务都通过HTTP依赖于大量外部各种接口的响应, 这些接口的响应时间不可控,有时候会出现响应时间过长的情况,这时候如果不做任何处理,那么这些请求就会一直等待,这样就会导致系统的响应时间过长,甚至出现系统崩溃的情况。 双十一期间,SISP客服系统出现了系统崩溃问题,经排查发现tomcat线程池被耗尽,进一步排查是因为所依赖的PIS接口响应慢了 简单来说问题大概长...
2019-12-12
线上ElasticJob堵塞问题排查
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Bug-Log-Optimization/elasticJob-bug-fix.html 背景 刚进新公司3天正逢双十一,领导生产补数出问题了,补数速度不稳定时快时慢,百万条数据补了好几个小时,之前都是几分钟搞定的,导致通了个宵; 早上我早到公司,领导截了个数据库的图给我,说交给我来看,然后刚通宵完的他就去开会汇报去了。。。我还没来得及熟悉环境,就被扔到了火坑里了,压力山大。。。 具体的过程没记录,这里只能凭回忆记录下了 问题描述 给我的截图大概长这样: 数据库分库号 需要补数的运单数量 分库0 12345 分库1 0 分库2 0 … *** 分库31 0 分库32 0 分库32 5w 分库33 4w 分库34 8w … *** 分库128 8w 知道的太少,跟同事了解业务,其实补数就是重推数据,把需要重推的单号记入表中,然后通过ElasticJob定时任务消费表中数据,实现重推数据 问题分析 没用过Ela...
2018-10-02
Spring-Cloud服务在Consul中的异常注册
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Bug-Log-Optimization/bug_in_spring-cloud_instance_registered_with_consul.html 优雅停机脚本见: shell-系统优雅停机 背景 公司实现微服务化并原来使用的Dubbo+Zookeeper实现应用间的服务调用,考虑到Dubbo不在维护最近想要切换为Spring Cloud+Consul 环境 Spring Cloud: Edgware.SR3 Spring-boot: 1.5.13.RELEASE 12345678910111213141516<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>1.5.13.RELEASE&l...
2023-05-11
关于上游同一数据大批量重复推送问题处理
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/same-data-push.html 先粗略写,日后有缘完善 背景 上游系统在推送数据到下游系统时,由于网络、代码、又或者是运维上(主要是sql重推没去重之类的),导致上游短时间推送大量同一单号给到OMS系统,导致数据库压力剧增 解决方案 新增字段,Version,接收上游数据时先判断Version是否比OMS的大,如果大则更新,否则不更新 Other More 为什么不只用数据库锁版本号或者锁版本号? 先确认概念: Version(数据版本号,解决的是数据新旧问题): version字段用于判断数据版本的新旧。在某些业务场景下,需要检查数据是否被其他操作修改过,以避免数据冲突或脏读的问题。通过比较version字段的值,可以判断当前数据是否是最新版本,如果版本不匹配,则可能意味着数据已被其他操作修改,需要采取相应的处理措施(如回滚、重新读取等)。 lockVersion(乐观锁锁版本号,解决数据并发更新问题): lockVersion...
