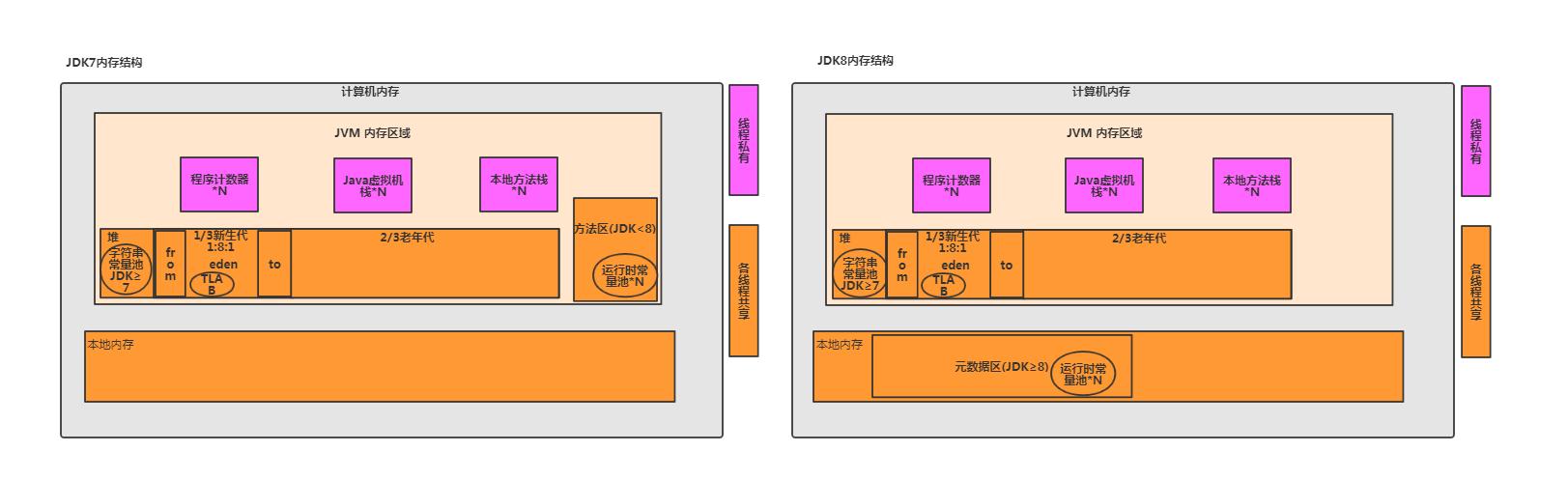
报表JVM调优
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/JVM/report-jvm-optimize.html
忘记记录了。。凭记忆记录下😂,下面是大概流程
背景
之前上线的一个新报表项目,我们的报表服务主要通过定时任务异步生成报表,报表比较大,每次运行时长长,实时性要求较低。
但在生产环境普罗米修斯监控中,发现服务频繁进行GC,且GC前后释放的内存不多,GC期间CPU占用略高。但是GC时长看着很短,为了解决这个问题,我进行了一次针对报表服务的JVM调优
过程
1. 看监控
使用Prometheus监控JVM指标,并结合Grafana进行数据可视化。通过Prometheus收集报表服务的JVM指标,如GC情况、内存使用、线程状态等
发现回收间隔时间较短,且回收前后大部分时候释放的内存不是特别多,但有时候却特别多,看了下GC配置,G1+默认200ms的回收间隔,估计是这个时间间隔搞个鬼,不太适合我们的业务场景(报表比较大,每次运行时长长)。
2. jstat确认GC前后内存变化
1 | jstat -gc 12345 1000 10 |
样例:
| S0C | S1C | S0U | S1U | EC | EU | OC | OU | MC | MU | CCSC | CCSU | YGC | YGCT | FGC | FGCT | GCT |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 68224.0 | 68224.0 | 0.0 | 34080.7 | 272896.0 | 272896.0 | 68224.0 | 68224.0 | 68224.0 | 27327.0 | 34080.7 | 10258.0 | 20 | 0.269 | 2 | 0.044 | 0.313 |
| 68224.0 | 68224.0 | 0.0 | 34080.7 | 272896.0 | 272896.0 | 68224.0 | 68224.0 | 68224.0 | 27327.0 | 34080.7 | 10258.0 | 20 | 0.269 | 2 | 0.044 | 0.313 |
结果发现
- 每次老年代回收率较高,报表服务的对象不该存放在老年代,
应该调整到新生代 - GC时间较短,我们用的是G1回收器,所以认为其实每次都
不能很好的回收足够的内存,导致频繁的GC
3. jmap确认内存占用
1 | jmap -dump:format=b,file=heapdump.hprof 12345 |
因为当前服务实时性与可用性要求不是特别高,直接打dump问题不大;
但如果是实时性要求较高的服务,可以使用jmap -histo:live 12345查看内存占用情况,然后再决定是否打dump:
1 | jmap -histo:live 12345 | sort -n -r -k 2 | head -10 # 类实例实例数前10 |
4. MAT分析dump
使用MAT(Memory Analyzer Tool)分析heap dump,找出内存中的大对象以及引用关系
结合源码,发现在处理历史巴枪数据导出大任务报表时,查询的是Hbase,因为业务关系,后端没有进行分段查询,前端也没有做太多限制,前端用户贪方便,直接把网点近3个月的巴枪数据一口气导出来了,后端接受请求把数据一口气都查询出来了,然后单个任务写入报表也创建了大量的临时对象,在多个任务运行时很容易触发GC,GC后又不能有效释放这些内存,导致频繁GC。
5. 做出的调整
其实这个问题就是因为GC频繁,以及新生代对象过快晋升导致的;解决就相对简单了:
- 调整G1的暂停时间目标(-XX:MaxGCPauseMillis=500,默认200)
2. 调整新生代晋升阈值(-XX:MaxTenuringThreshold=20,默认15)本来想调整这个参数,但是从对象头决定了该参数最大值就是15(4个byte),无法调整哦…调整MaxGCPauseMillis就行了,G1回收器会自动调整新生代与老年代比例,如果后期还不行,可以考虑调整G1ReservePercent参数(老年代会预留的空间来给新生代的对象晋升,默认10%) - 调整业务限制,该巴枪扫描业务单次查询数量限制30天内,业务代码内进行7天一段分段查询,单次查询数据量限制在10w内,以防单次处理量过大,消耗大量内存
- habse工具类调整,查询habse单次限制在10w,业务调用时按需扩大、缩小,以防再次出现类似问题
- 新生代与老年代稳妥起见的比例暂不调整,因为该服务还加在了大量本地缓存等,理论上老年代还是相对要比较大一点的
- 除此以外,其实把垃圾回收器换成Parallel GC可能会更好,但是考虑到系统迭代会有更多的报表任务需要处理,以后内存可能还要逐步加,对大内存来说,还是先继续用G1吧
6. 效果
通过以上调优措施,报表服务的老年代回收率得到了有效改善,频繁GC现象得到缓解,进而提升了服务的性能和稳定性。
7. 其他顺手优化
巡检了一下,Cache服务(-Xmx4g -Xms4g)不单独提供服务,主要负责数据消费与写入,注重吞吐量,对停顿几乎无要求,当前使用的是CMS,同时也因为预留空间的特性浪费内存;不妥,正式改用Parallel GC。
优化后,通过jstat -gc 12345 1000 10查看老年代的使用率能打满,合理。
8. 其他参考记录
- 不要手动设置新生代和老年代的大小,只设置堆的大小
G1收集器在运行过程中,会自己调整新生代和老年代的大小,如果手动设置了大小就意味着放弃了G1的自动调优
- 主要调优目标:MaxGCPauseMillis
默认值为200ms,如果暂停时间设置的太短,就会导致出现G1跟不上垃圾产生的速度,最终退化成Full GC
- MixedGC调优
- -XX:InitiatingHeapOccupancyPercent
通过-XX:InitiatingHeapOccupancyPercent指定触发全局并发标记的老年代使用占比,默认值45%,也就是老年代占堆的比例超过45%。如果Mixed GC周期结束后老年代使用率还是超过45%,那么会再次触发全局并发标记过程,这样就会导致频繁的老年代GC,影响应用吞吐量。同时老年代空间不大,Mixed GC回收的空间肯定是偏少的。可以适当调高IHOP的值,当然如果此值太高,很容易导致年轻代晋升失败而触发Full GC,所以需要多次调整测试- -XX:G1MixedGCLiveThresholdPercent
通过-XX:G1MixedGCLiveThresholdPercent指定被纳入Cset的Region的存活空间占比阈值,不同版本默认值不同,有65%和85%。在全局并发标记阶段,如果一个Region的存活对象的空间占比低于此值,则会被纳入Cset。此值直接影响到Mixed GC选择回收的区域,当发现GC时间较长时,可以尝试调低此阈值,尽量优先选择回收垃圾占比高的Region,但此举也可能导致垃圾回收的不够彻底,最终触发Full GC
附录:优化前系统垃圾回收器选型
- admin(-Xmx8g -Xms8g)服务于前端,提供实时同步的http接口,注重高效响应,当前使用的是默认的Parallel GC,应该考虑使用
CMSG1回收器,并限制最大停顿时间<20 - Cache(-Xmx4g -Xms4g)不单独提供服务,主要负责数据消费与写入,注重吞吐量,当前使用的是CMS,不妥,应考虑使用Parallel GC
- Report(-Xmx5g -Xms5g),主要报表异步导出,注重吞吐量,当前使用的是G1,其实用Parallel GC可能也差不多
- Order:(Xmx4G -Xms4G),G1回收器,注重吞吐量,或许Parallel也是个很好的选择
- Operation:(Xmx12G -Xms12G) 想说G1回收器没跑了,目前也是用的这个,但作为数据消费者与生产者其实基本不怎么GC,其业务只注重吞吐量,其实或许Parallel也是个很好的选择,但这是个坑,因为这可能导致超长停顿,让与中间件等服务器之间的连接超时,出现故障