
MQ常见问题及其处理方案
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/MQ/mq-common-problem.html
基于Rabbitmq:


本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 花火笔记!
相关推荐
2021-01-12
消息中间件-kafka
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/MQ/mq-kafka.html 1. 为什么 Kafka 快 1.1 通过生产和缓冲区减少网络开销 Kafka 的生产者发送消息时,会将多条消息打包为一个 batch(发送缓冲区)一起发送,等缓冲区大小达到阈值或者一定时间,批量发送,从而减少网络开销 1.2 根据不同 ack 配置,可以不刷盘、少刷盘就响应 ack ack=0:生产者发送消息后,不会等待 Broker 的响应,不保证消息是否到达 Broker ack=1:生产者发送消息后,等待 Leader Broker 接收到消息后,返回 ACK 响应 acks=all 或 acks=-1:生产者发送消息后,等待 Leader Broker 接收到消息,并且等待其他所有副本都成功复制消息(落盘),才会返回 ACK 响应 **注**: 节点接收到数据后不会立即刷盘,会先暂存到 pagecache 里,等到一定的大小或者时间后才会刷盘 1.3 零拷贝 正常 IO 需要经过 5 次读写才能从磁盘读取数据发送给消...
2021-01-09
消息中间件-Rabbitmq
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/MQ/mq-rabbitmq.html RabbitMQ是一款开源的消息中间件,采用AMQP(高级消息队列协议)作为底层协议,提供了可靠的消息传递机制、灵活的路由方式以及多种消息发布/订阅模式等特性,被广泛应用于分布式系统、微服务架构等场景中 数据发布方式 RabbitMQ支持多种消息发布方式,主要包括以下几种: 1. P2P(点对点)模式 P2P模式是最简单的消息发布方式,即消息生产者直接将消息发送到指定的队列中,消费者通过消费该队列中的消息来获取数据 2. 发布/订阅模式 发布/订阅模式是指生产者将消息发送到一个交换机(exchange)中,而消费者则创建一个或多个队列并绑定到该交换机上,从而获取该交换机中的消息 在发布/订阅模式中,可以使用Fanout类型的exchange,该类型的交换机将消息广播给所有绑定到该交换机上的队列 3. Routing模式(路由模式) Routing模式是指生产者将消息发送到一个Direct类型的交换机中,交换机将消息交给符合...
2019-05-22
Spring白板源码整理
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Spring/Spring-whiteboard.html 这本经常出错的辣鸡书的读后整理:《Spring源码深度解析》 仅记录,日后有空加描述,嗯,有空的话,有空再说。。。 SpringAOP源码 Spring事务源码 SpringMVC Spring DispatcherServlet源码 Spring+Mybatis整合原理源码分析 Spring整合MyBatis的原理是将MyBatis的SqlSessionFactory和Spring的IoC容器进行集成,从而在Spring容器中管理SqlSessionFactory对象,进而管理MyBatis的SqlSession对象 在Spring整合MyBatis的过程中,主要用到了以下几个FactoryBean: SqlSessionFactoryBean: 它是一个FactoryBean,用于创建SqlSessionFactory对象,并将其纳入Spring容器进行管理。它通过配置DataSource等参数,...
2021-05-04
数据库数据倾斜
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Bug-Log-Optimization/database-skew.html 其实改动不是很大,这里简单记录下 背景 OMS订单系统,日数据量较大平均近3kw/日,高峰达8kw+/日的订单需要存到数据库中(之前64库,现在扩到了128库); 运维后台监控看到,各个库的压力不一,江浙沪,京津冀,深圳755等地区对应的数据库压力很高,而其他地区的数据库压力很低; 分析 数据库通过mycat,以分库号字段进行分库,以内部订单号分表 内部订单号规则: 3位分库号+系统来源(2位)+MMDDHHmmssSSS+订单类型+6位随机数+1位校验码=26位 分库号生成规则为根据地区、网点进行生成; 因此,可以看出,同一地区的订单,分库号是一样的,因此,同一地区的订单,会落在同一个库中; 解决 直接粗暴修改分库号生成规则为0~127区间随机生成,因为原有订单的删、改、查最终都会带上原有的内部订单号,所以不会影响到历史数据,只是新的订单会落在不同的库中; 上线方案 因为是S级系统...
2022-01-04
缓存密集加载导致数据库崩溃问题
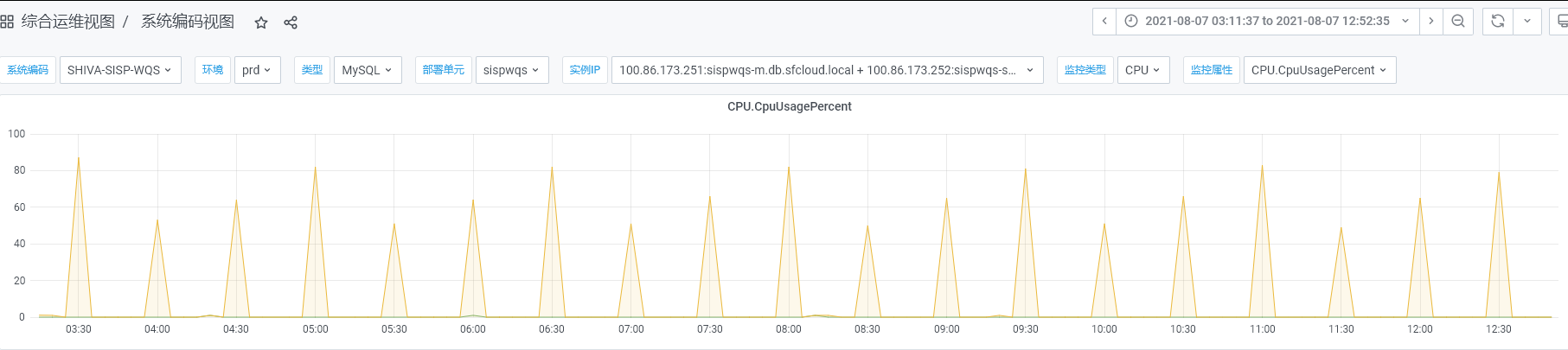
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Bug-Log-Optimization/cache-load-database-crash.html 背景 SISP自己基本不存储业务数据,但是每个节点都需要本地缓存了一些网点、员工信息、月结用户信息等基础数据,生产监控发现数据库定期压力飙升,数据库CPU压力到达80+%如图: 用脚趾头分析 从图中可以看出,每天小时飙升一次,明显就是定时任务大批量查询数据库导致的,在SISP系统,也就只有加载缓存可能会导致 找到运维获取慢日志,发现大量的查询语句,如下: 12345SELECT DISTINCT nd.division_code AS city_code, nnd.dist_cn_name , nnd.dist_en_name FROM tm_new_district nd, tm_new_district nnd WHERE nd.division_code IN( SELECT DISTINCT t.CITY_CODE FROM t...
2019-12-31
Kafka延时队列方案探讨
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/Kafka-Delay-Queue.html 目前在用方案:直接重新丢回队列后面 实现逻辑 引入延迟消息消费服务,消费延迟消息 每条消息消费时,Sleep3秒(很长),再处理; 处理时判断是否到点,没到点的数据丢回kafka 优点 不引入新依赖(不依赖DB,不依赖其他第三方) 缺点 1. 处理效率慢,并发低 2. 延时时间不精准,颗粒度非常大 3. 浪费Kafka空间,同一数据在Kafka多次存储(其实Kafka底层是一种文件/文档存储,消息的消费只读不删) 优化方案1: 延迟消息存DB,通过Redis的zset结构支持 ### 实现逻辑 #### 1. 发送延时消息: > 延时消息发送到延时队列TopicA ### 2. 消费延时消息: > 延时程序(消费者)消费延迟队列的消息,把延时消息存入DB,再把[发送时间]+[延时消息在DB记录ID]作为zset设到Redis ### 3. 监控&&发送[到时的消息]: > 1....
