每天进步一点点(持续更新)
[原创]这篇只是做点记录备忘,个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Make-A-Little-Progress-Every-Day/Make-A-Little-Progress-Every-Day.html
2022-10-25
目前本地缓存使用的方式
- 订运单系统: SF自研的类Ehcache框架,存储的内容不是特别多,都是一些网点月结卡号信息,所有对象存在于Map,占200m左右
- SISP系统: 使用了Caffeine,存储的内容,存储的内容很多,包括员工表(900m),人员表(bdus 800m) 客户表(1.2g),用户及权限相关表(500m)
- 关联后约占4g内存,目前采用Caffeine默认存储方式,启动即全量加载(极个别采用懒加载方式加载),全部存在于Map中,即堆存储
优化: 缓存为基础数据,数据量稳定,目前采用CMS回收器,堆空间8g,缓存存于堆中,占约4g,平时MajorGC达4~6s,曾出现高峰gc达52s,
应考虑将缓存存于堆外,减少GC的压力,提升性能(风险点,可能会导致内存溢出)后面自己论证时行不通...因为java对象存到堆外时需要额外进行序列化,经测试,这会导致对象明显变大,浪费的内存有点多,在降本增效的背景下是行不通的
2022-10-20
Spring中最常用的11个扩展点
2022-09-02
Hystrix熔断配置
为让Hystrix的熔断降级配置更加合理,会议讨论结果需进行如下优化,
- 为每个已有Hystrix熔断的接口设置最高并发配置(execution.isolation.semaphore.maxConcurrentRequests),配置200~500之间,具体计算方式
单节点线程数 = QPS /节点数/ ( 1000 / 被熔断方法的P99耗时ms )
翻译:方法单节点线程并发数 = QPS /节点数/1s内该方法能执行次数 - 把Hystrix配置提取到disconf,重启生效,无需发版
QPS和RT的关系:
对于单线程:QPS=1000/P99
对于多线程:QPS=1000线程数量/P99
对于多线程多接点:QPS=1000单节点线程数量*节点数量/P99
2022-08-11
前端跨域请求减少Option请求
后端对CorsConfiguration配置Access-Control-Max-Age,前端请求时接收到Access-Control-Max-Age,在该有效时间内不会再发出Option请求
CorsConfiguration config = new CorsConfiguration();
config.setMaxAge(600L);
后端返回的Access-Control-Max-Age 大于浏览器支持的最大值 那么取浏览器最大值作为缓存时间
否则取后端返回的Access-Control-Max-Age作为缓存时间
缓存时间内不会再发option请求
源码
2022-06-03
POJO、JavaBeans、BO、DTO 和 VO 、DO之间的区别
- POJO,也称为普通旧 Java 对象,是一个普通的 Java 对象,它没有对任何特定框架的引用。
- JavaBean/BO:有约束的POJO,国内用法一般为BO
- 实现Serializable接口
- 将属性标记为private
- 使用 getter/setter 方法来访问属性
- DTO:也称为数据传输对象,封装值以在进程或网络之间传输数据。
DTO 没有任何显式行为。它基本上有助于通过将域模型与表示层解耦来使代码松散耦合
- VO:外国作为值对象,不过国内用法是用来做视图对象,主要是返回前端用的对象
- DO(Data Object) ,持久化对象,数据库对象
2021-06-01
System.arraycopy方法和Arrays.copyOf()
- System.arraycopy方法:是本地方法,如果是数组比较大,那么使用System.arraycopy会比较有优势,因为其使用的是内存复制,省去了大量的数组寻址访问等时间
- Arrays.copyOf()
- Arrays.copyOf()在System.arraycopy()实现的基础上提供了额外的功能
- 会创建新数组
- 允许与原数组类型不同,但是这样会调用JVM的反射,性能较差
2021-05-20
ES 分词
- text:用于全文索引,该类型的字段将通过分词器进行分词,最终用于构建索引
- keyword:不分词,只能搜索该字段的完整的值,只~~~~用于条件精准查询
通常情况都以 keyworkd 字段进行搜索,因为全文索引的分词器不一定能够完全分词,可能会导致搜索不准确,所以一般都是用 keyword 字段进行搜索
2021-02-26
HBASE 列族,RowKey
HBase是一种面向列的数据库,以row+列名作为key,data作为value,依次存放 假如某一行的某一个列没有数据,则直接跳过该列。对于稀疏矩阵的大表,HBase能节省空间
- 表是行的集合
- 行是列族的集合
- 列族是列的集合
- 列是键值对的集合
2021-02-08
最近要搞懂的事情
- redo log和checkpoint机制
单机情况下,MySQL的innodb通过redo log和checkpoint机制来保证数据的完整性。因为怕log越写越大,占用过多磁盘,而且当log特别大的时候,恢复起来也比较耗时。而checkpoint的出现就是为了解决这些问题。
- mysql主从架构
Master-Slave(主挂了可能会丢失一部分数据)和Group Replication 的架构(mgr采用paxos协议实现了数据节点的强同步,保证了所有节点都可以写数据,并且所有节点读到的也是最新的数据)
2021-02-07
稍稍记录一下2020年干过的那些P大点的事
- 协助完成Redis降存储–>阉割无用字段,(没用上压缩) ,以前是存储整个对象,现在是存储个别有用的字段, 降低了60%~80%的存储
- 综合订单、CX、操作运单、公共redis,共节省redis资源9034G
- 团队共同完成灰度发版–>中间加应用,数据先到分流应用,通过分流应用把对应城市、网点的数据分流到对应的应用
- 独立完成ES查询优化–>优化判断索引逻辑,指定查询具体某个分片,提高性能550倍
- 生产某个节点线程数过多及CPU高–>dump&排查源码 elasticJob的采用了流式处理,有某个节点的一些线程一直能查到数据,就一直继续工作了;
- elastic-job流式处理导致最终只有一个线程在跑的问题排查&修复 —> 同上
- 重试模块加入根据重试次数逃生逻辑,防止异常时空跑把系统跑死
- 优化ES存储订单数据的结构 —> 4亿+数据量减少到只剩下5kw数据量,降低了十倍左右
- 把orderExtendInfoList类型改为keyword类型(原来为嵌套类型), 内部额外存储一个作为索引用的值为原orderExtendInfo的key和value对应的Map
描述起来比较麻烦 大概是把下图左边的变成变成右边的

数据造就业务—>咋玩???
- 目前手上有啥数据:
订单–>可以对BSP客户进行分类, 对不同类型客户,可以特别推荐一些增值服务或产品
----->根据寄件商品的类型为其推荐增值服务
扩展信息…没啥用
增值服务订单状态<—监控? 存在很多很久不揽收的 进行告警通知小哥? 让其决定是取消,还是让其再设定一个较远的预约时间
FVP所有状态<–
运单号生成
运单<—
产品变更<— 变更监控? 至少可以记录一下产品变化以及运费变化
2021-01-25
一、ZK事件回调原理 – 最近用得少老是忘记,还是记录一下吧
简单来说,就是客户端启动后,会在zk注册一个watcher监听某个我们关心的节点Node的变化;
同时客户端会把这个watcher存到本地的WatcherManager里;
当这个节点出现变化,zk会通知到对应的客户端,调用该watcher的回调方法(process方法)。以此方式实现动态配置平台的配置刷新下发、分布式锁等功能
2020-12-14
一、 ElasticSearch原理
- 精确查询
term 查询是如何工作的? Elasticsearch 会在倒排索引中查找包括某 term 的所有文档
- Lucene Index(包含多个Segments):
Segments 是不可变的(immutable):
Segments Delete?当删除发生时,Lucene 做的只是将其标志位置为删除,但是文件还是会在它原来的地方,不会发生改变。
Segments Update?所以对于更新来说,本质上它做的工作是:先删除,然后重新索引(Re-index)
随处可见的压缩:Lucene 非常擅长压缩数据,基本上所有教科书上的压缩方式,都能在 Lucene 中找到
缓存所有的所有:Lucene 也会将所有的信息做缓存,这大大提高了它的查询效率
- 整体结构
Cluster由多个Node节点组成
每个Node节点由多个索引Index组成
每个索引由多个Share组成
每个Share(又叫Lucene Index)存在于集群中多个Node中,具体有多少个Share,看你索引的配置,由多个Segment组成
每个Segment(又称Mini索引),每个Segment都是不可变的,只会生成一个增量Segment(含修改后的/新增的数据),原来的数据只能标记为删除,当Segment多了之后会做merge合并操作;
- Segments的创建&刷新 (没玩大数据 大概了解就行了)
进行索引文档后,看是否有达到flush条件的Segment,存在就flush该Segment将该数据刷到硬盘中,没找到就创建一个Segment??
参考 -> ES lucene写入流程,segment产生机制源码分析
2020-11-18
一、 MYSQL是怎么运行的 – 连接原理
–以下为内连接,驱动表为t1,如果t1通过where过滤完还有2条数据,那么会去t2表查询2次
select * from t1 join t2 where ***;
select * from t1 inner join t2 where ***;
select * from t1 cross join t2 where ***;
(以上等价于)select * from t1,t2 where ***;
select * from t1 left join t2 on t1.a=t2.a where ***; – 为外连接
on实际是给外连接用的,在内连接使用的话和where的作用是一样的;
在外连接中使用,如果匹配不上,不会过滤掉驱动表原有的值;如果要过滤掉这种连接不上的值,可以再加个where条件过滤
驱动表t1只会被访问一次,被驱动表t2会被访问多次
2020-09-24(好久没做记录了…)
一、 DB 看似匹配到索引,但是没有走索引的情况(注意事项)
因类型转换导致不走索引
- 建表语句cell的数据类型为Varchar
create table t (
id int(20) primary key AUTO_INCREMENT,
cell varchar(20) unique
)engine=innodb;
建表的时候cell定义的是字符串类型
- Explain

通过explain,基本已经可以判断:
update t set cell=456 where cell=55555555555;
并没有和我们预想一样,走cell索引进行查询,而是走了PK索引进行了全表扫描。
- 实际问题
where语句cell类型与索引的不匹配,不会走索引,最终会走全表;
- 结论
类型转换,会导致全表扫描,出现锁升级,锁住全部记录
二、 DB 执行计划查看&&死锁排查
执行计划
select_type:SIMPLE
这是一个简单类型的SQL语句,不含子查询或者UNION。type:index
访问类型,即找到所需数据使用的遍历方式,潜在的方式有:
(1)ALL(Full Table Scan):全表扫描;
(2)index:走索引的全表扫描;
(3)range:命中where子句的范围索引扫描;
(4)ref/eq_ref:非唯一索引/唯一索引单值扫描;
(5)const/system:常量扫描;
(6)NULL:不用访问表;
上述扫描方式,ALL最慢,逐步变快,NULL最快。possible_keys:NULL
可能在哪个索引找到记录。key:PRIMARY
实际使用索引。ref:NULL
哪些列,或者常量用于查找索引上的值。rows:5
找到所需记录,预估需要读取的行数。
死锁排查
- 有权限的mysql账户执行:
show engine innodb status;
- 根据查到的结果 分析LATEST DETECTED DEADLOCK里的内容
三、ES 提高查询效率
学习自: ES 在数据量很大的情况下(数十亿级别)如何提高查询效率
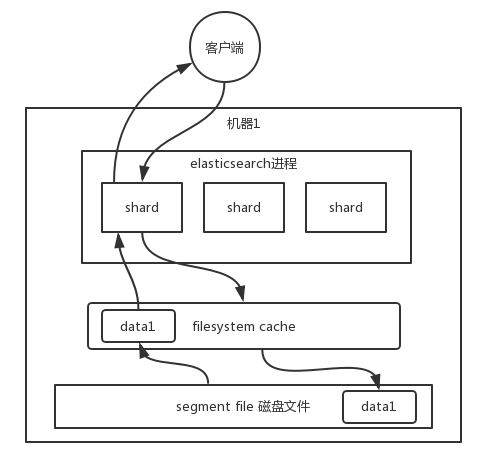
- 把尽可能多的索引放在
filesystem cache中 - 不做复杂查询(Join等),如果有这样的需要,应以设计得更好的document(记录)来实现简单查询(单表)
- 使用ES+hbase架构:
ES存索引,索引全放在filesystem cache,数据存HBase;通过ES进行条件查询,获取docId,用该docId去查HBase - 禁止深度查询,使用scrollApi或search_after代替
四、ES存储结构
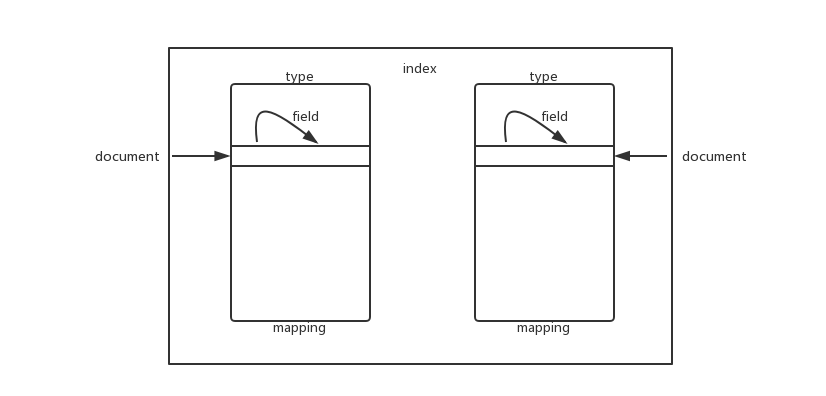
index -> type -> mapping -> document -> field
实例: order~2020-08-02/order/_mapping/记录/字段
翻译: 索引名称/表名/表结构/记录/字段
2019-12-19
Kafka
- 基础点
Topic&消费组:
一个Topic的一个Partition只能一个Consumer Group的一个节点消费
一个【Topic】对应多个【Partition】(文件)
消息大小限制:
一条消息 默认最大只能为1000000B(976.56 kB),所以一般规定不允许发送>900k的消息
- 版本区别:
0.8版本 (相对历史版本 支持了Replication高可用 )
当时只有Consumer Coordinator
coordinator需要依赖于ZK,通过zk监听/consumers//ids变化 与 brokers/topic的数据变化决定是否要 rebalanced
rebalanced后,consumer自己决定自己要消费哪些Partition,然后抢先在/consumers//owners/ / 下注册(通过这种方式实现一个Topic的一个Partition只能一个Consumer Group的一个节点消费`)
同时,各个Consumer Coordinator还需要进行位移的提交弊端: 消费者自己决定消费哪些分区,各个Consumer Coordinator还需要进行位移的提交
并且分区的决定与位移的提交都需要依赖于ZK0.8.2版本
0.8.2版本开始同时支持将 offset 存于 Zookeeper 中与将offset 存于专用的Kafka Topic 中,但是需要High Level API的支持,且BUG较多,目前公司用的还是Low Level Api0.9.x版本
新增Group Coordinator,存在于Broker端
代替了0.8.x版本的zk,每个消费组对应一个,负责每个消费者位移的提交&分区消费的决策0.10+
消息结构添加了时间戳,可根据这个时间戳实现延迟队列0.11.x版本
新增了对【幂等】、【事务】的支持(依赖于Producer幂等) (exactly-once)
3.High Level和Low Level
将仅支持zookeeper维护offset方式的高级抽象的API称为 Low Level Api,高度抽象,将支持kafka broker 维护offset方式抽象低的API的称为 High Level API ,
High level consumer vs. Low level consumer
官方解释(看最下面的描述)
- 消息(生产)幂等
每个Topic的每个Partition对每个生产者都维护了一套ID(UUID)
生产者每次发送消息时候,消息体都带上这个ID+1,以此Broker可得知:
- 当消息的squence number等于broker维护的squence number + 1,表示消息有序且第一次消费
- 当消息的squence number小于或等于broker维护的squence number,表示重复消费额
- 当消息的squence number等于broker维护的squence number + n(n > 1),表示存在消息丢失
参考1:Kafka Producer 幂等的原理
参考2:上半场的幂等性设计
- 消息的分区选择:
一条消息会根据Key被路由到某一【Partition】(key=0对应分区0);如果没有指定key,消息会被均匀的分配到所有分区;目前我们封装的方案是,不管有没有Key,都会被随机打乱到每个分区)
每隔 topic.metadata.refresh.interval.ms 的时间,随机选择一个partition。这个时间窗口内的所有记录发送到这个partition。发送数据出错后也会重新选择一个partition
对key求hash,然后对partition数量求模: Utils.abs(key.hashCode) % numPartitions
代码: kafka.producer.async.DefaultEventHandler#handle
- Kafka支持的消息发送模式
At most once 消息可能会丢,但绝不会重复传输(例:读到先Commit,再处理)
At least one 消息绝不会丢,但可能会重复传输(例:读到先处理,再Commit)
Exactly once 每条消息肯定会被传输一次且仅传输一次,很多时候这是用户所想要的 (0.8.2版本还不支持)
高可用
kafka默认会重试3次零碎小点
- Kafka实现的是客户端软负载: 让producer决定丢到哪个partition里
- Consumer端仅支持pull模式,这也有利于让Consumer端决定消费速率
- Consumer不能消费太久(如Sleep),因为Kafka会认为程序宕了,分区会重新进行分配,把消息分给其他的Consumer (相关配置项: max.poll.interval.ms)
- Consumer每次可从Kafka取max.poll.records条数据进行处理
- 如果想要消息有序 那么就得保证同个业务key的消息都是发到1个分区里
Redis-Sentinel&Jedis
通过Sentinel集群获取Redis主节点原理
SF-Sentinel中配置Redis链(mymaster1,mymaster2,mymaster3),然后获取每一条链的Master,进行初始化Redis连接池
原生的Sentinel中配置Redis链,然后获取该链的Master,进行初始化Redis连接池
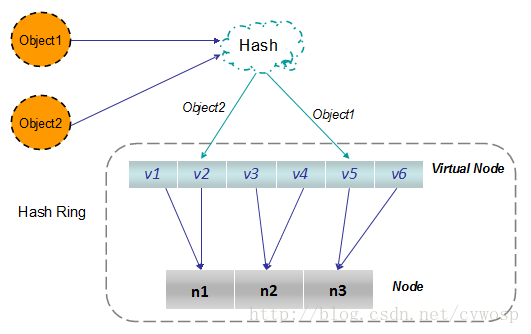
Jedie的Key是如何被存入Redis的某个节点的
Jedis初始化时会初始化160个虚拟节点,160个虚拟节点通过Map(Map<ShardInfo
, R> resources)映射到实际的Redis-Master节点
Jedis在Set key时会对Key分片计算(计算落在160个节点的哪一个),然后再根据虚拟节点与实际节点的映射,把指令发给实际的节点
参考代码:
redis.clients.util.Sharded#initialize
redis.clients.util.Sharded#getShard(byte[])
Redis-Sentinel模式是如何扩容的
空
Jedis一致性分析
2019-11-28
git rebase -i HEAD~2
pick:保留该commit(缩写:p)
reword:保留该commit,但我需要修改该commit的注释(缩写:r)
edit:保留该commit, 但我要停下来修改该提交(不仅仅修改注释)(缩写:e)
squash:将该commit和前一个commit合并(缩写:s)
fixup:将该commit和前一个commit合并,但我不要保留该提交的注释信息(缩写:f)
exec:执行shell命令(缩写:x)
drop:我要丢弃该commit(缩写:d)
Hibernate 基本知识
- inverse属性表示本实体是否拥有主动权
inverse只有在非many方才有,也就是many-to-many或者one-to-many的set,List等
2019-11-25
数据库count()
官方解释
Returns a count of the number of non-NULL values of expr in the rows retrieved by a SELECT statement. The result is a BIGINT value.
返回行中 expr 的非 NULL 值的计数
count(*) 和 count(1)
5.7.18以后,两个函数执行计划都是一样的
- 如果该表没有任何索引,那么会扫描全表,统计行数
- 如果该表只有一个主键索引,没有任何二级索引的情况下,那么通过主键索引来统计行数的
- 如果该表有二级索引,则会通过占用空间最小的字段的二级索引进行统计
count(column)
如果字段定义为not null,则按行累加,如果允许有null,则会把值取出来判断一下是不是null,将不是null的值累加返回。
MyISAM 与 InnoDB
- MyISAM会记录每个表的行数,count()时直接返回
- InnoDB会通过扫描全表或索引,得到行数
- 在使用count函数中加上where条件时,在两个存储引擎中的效果是一样的,都会扫描全表计算某字段有值项的次数
DB select count速度
count(*)=count(1)>count(primary key)>count(column)
参考
MySQL原理:count(*)为什么这么慢,带你重新认识count的方方面面
2019-11-22
[垂直]分库分表
目标
通过减少数据量,提升性能
原则
- 长度较短,访问频率较高的属性尽量放在一个表里,我们将其称为主表
(base表) - 字段较长,访问频率较低的属性尽量放在一个表里,我们将其称为扩展表
(ext表) - 经常一起访问的属性,也可以放在一个表里
(备选)
大数据量场景注意事项
- 不能用Join
解决方式: 让应用自己拆分成两次查询
- base表和ext表不能Join,因为一旦Join了,那么两张表就出现了耦合,这不利于日后拆表到别的数据库实例上
- Join很消耗数据库的性能
(分布式场景下,瓶颈往往是数据库)
提高性能的原理
- 减少单表的数据量,减少磁盘IO
(降低每行记录大小) - 更好的利用缓存
因为减少单表数据量还可以充分利用数据库缓存,减少磁盘IO
2019-11-20
数据库基本知识
MyISAM与InnoDB索引的区别
MyISAM:
- MyISAM不存在聚集索引,主键索引与普通索引没区别,叶子节点都是存储的都是数据的地址
InnoDB:
- InnoDB必然有[一个]聚集索引
(为主键索引,没主键时会用第一个非空普通索引,都没有会生成一个基于行号的聚集索引)
select * from t where name=‘lisi’;
会先通过name辅助索引定位到B+树的叶子节点得到id=5,再通过聚集索引定位到行记录
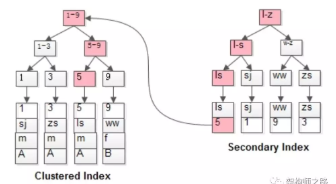
违反唯一索引场景:
MyISAM会出现一个update语句,部分执行成功,部分执行失败(因为不支持事务)
2019-11-11
Elastic-Job
- 运行规则:
3台机器的一个集群 ,shardingCount=10 ,分片结果为:1=[0,1,2,9], 2=[3,4,5], 3=[6,7,8] (参考
AverageAllocationJobShardingStrategy)
如果本机的数据分片分到了多个分片(即一个JVM进程分到了多个分片),则Elastic-Job会为每一个分片去启动一个线程来执行分片任务 - 线程:
每个任务对应一个线程池,其默认线程数为: 2*逻辑核心数(参考
DefaultExecutorServiceHandler)
线程池配置为:new ThreadPoolExecutor(threadSize, threadSize, 5L, TimeUnit.MINUTES, workQueue, new BasicThreadFactory.Builder().namingPattern(Joiner.on("-").join(namingPattern, "%s")).build());(参考ExecutorServiceObject) - 问题:
要注意单机线程数要 大于 单机获取到的分片数 - 参考 《Elastic job 线程模型 源码分析》
一个jvm实例 处理多个 job , 每个job 在该实例上分片数又大于逻辑核心数*2 的数量
随着job不断增加 , 单个job任务执行时间可能会变长 ,有可能超过平时的任务完成超时时间 ,造成任务失败举个例子:
如果一台机器 处理器数 2 , 线程池 就是 4 , 如果 分片是 5 , 就是说 一个分片会被排队 ,实际完成时间 >2 个分片 完成时间
Elastic-Job其他
1. 失效转移
【简单的HA】版失效转移 (默认)
在作业节点下线,或者zk的session超时(默认60s)时,会在下一轮任务分片时,把这个该问题节点的分片分给别的正常节点进行作业 (可能会存在作业重复处理的问题)【真正的】'失败’转移 (需要开启)
当failover(默认值为false)配置为true时,才会启动真正的失效转移;
当failover(默认值为false)和monitorExecution(默认值是true)这两个配置都为true时 只有对monitorExecution为true的情况下才可以开启失效转移;
如果任务1在A节点执行【失败】,那么会【转移】给别的存活的节点【竞争】执行这个任务1;
2019-08-26
MySQL锁
- InnoDB锁机制是基于索引建立的
- 如果SQL语句中匹配不到索引,那么就会升级为表锁
记录锁
1 | -- id 列为主键列或唯一索引列 |
通过唯一索引实现的记录锁,只会锁住当前记录(必须为
=不然会退化为临键锁)
间隙锁
- 间隙锁只有在事务隔离级别 RR(可重复读)中才会生效.
- 为非唯一索引组成(如class,age等)
1 | select student where age>26 and age<28 lock in share mode ; -- 这里以读锁为例 |
使用间隙锁的条件
- 命中普通索引锁定;
- 使用多列唯一索引;
- 使用唯一索引命中多行记录
临键锁(Next-key Locks)
- 临键锁只有在事务隔离级别 RR(可重复读)中才会生效.
- 是记录锁与间隙锁的组合
- 可以是
唯一索引,也可以是非唯一索引,对其都以间隙锁的形式进行锁定(以唯一索引匹配,并且只匹配到一条数据除外)
临键锁(Next-key Locks) 例子:
tno(唯一索引) | tname | tsex | tbirthday | prof | depart | age(非唯一索引) |
|---|---|---|---|---|---|---|
| 858 | 张旭 | 1 | 1969-03-12 | 讲师 | 电子工程系 | 25 |
| 857 | 张旭 | 女1 | 1969-03-12 | 讲师 | 电子工程系 | 25 |
| 856 | 张旭 | 男 | 1969-03-12 | 讲师 | 电子工程系 | 25 |
| 831 | 刘冰 | 女 | 1977-08-14 | 助教 | 电子工程系 | 29 |
| 825 | 王萍 | 女 | 1972-05-05 | 助教 | 计算机系 | 28 |
| 804 | 李诚 | 男 | 1958-12-02 | 副教授 | 计算机系 | 26 |
其中有唯一索引的
临键为:
(-∞,804]
(804,825]
(825,831]
(831,856]
(856,857]
(857,858]
(858,+∞]
其中有非唯一索引的
临键为:
(-∞,25]
(25,26]
(26,28]
(28,29]
(29,+∞]
非唯一索引临键锁验证
1 | -- session1 |
这时候会锁定非唯一索引的
临键(25,29]
所以我们测试更新age=25–>成功 插入age=27阻塞 更新age=29阻塞 插入age=30成功即可验证
1 | -- session2 |
唯一索引临键锁验证
1 | -- session1 |
根据上面的sql,我们匹配到
唯一索引临键锁为:(825,857]
所以我们测试更新tno=825–>成功 更新tno=857阻塞 更新age=858成功即可验证
1 | -- 更新tno="825"-->成功 |
2019-08-22
Spring事务/AOP增强
@EnableAspectJAutoProxy(exposeProxy = true)
- 进入代理时,通过
AopContext.serCurrentProxy(proxy)把当前代理设置到ThreadLocal中 - 后续在线程销毁(请求结束)前调用代理内部之间的调用就可以通过
((AService)AopContext.currentProxy()).b()进行调用了 - PS. 性能影响不大 不过实际上代理内部之间还需要AOP增强的场景不多,一般没必要用
Spring LTW实现的静态织入(应该不能叫做代理)
- 需要添加配置:
- 代码添加:
@EnableLoadTimeWeaving(aspectjWeaving=ENABLED)或<context:load-time-weaver aspectj-weaving="enable" />- 添加JVM参数
-javaagent:类加载器代理路径
LTW(LoadTime Weaving)
加载时织入。在通过JVM加载类时候会先调用ClassTransformer的transform()进行字节码替换后才会进行加载。静态AOP
通过LTW可以实现静态AOP增强,加载到的类就是已经增强后的代码。这样我们调用方法的时候,直接就是调用了增强后的方法,比起动态代理的调用,更加地高效。
上述流程大致如下所示:
graph TD A[Target] B[增强后的字节码] C[加载后的代码] D[注入后的Bean] E[调用方] A--ClassTransformer的transform方法进行字节码植入-->B B--JVM加载-->C C--Spring使用,创建/注入Bean-->D E--方法调用-->D
2019-08-01
Spring事务
对于this.b()这些类实例的内部调用,b()实际上是无事务的
但是可以用((AService)AopContext.currentProxy()).b()结合@EnableAspectJAutoProxy(exposeProxy = true)这样b()就包裹在事务里了
2019-7-20
seata
- seata需要管理所有的数据库操作,不然不能通过前镜像进行回滚
2019-7-17
Spring事务/Cglib
- final,static,private修饰符无法被增强
由于使用final,static,private修饰符的方法都不能被子类覆盖,相应的,这些方法将不能被实施的AOP增强
- 增强应该作用在实现类中
@Transactional 注解可以作用于接口、接口方法、类以及类方法上,但是 Spring 建议不要在接口或者接口方法上使用该注解,因为这只有在使用基于接口的代理时它才会生效。
2019-5-20
【GC日志】GC耗时解析
【Time: user=0.71 sys=0.01 real=0.02 secs】
- user表示:本次GC过程中【所有线程】在用户态消耗的时间总和
- sys表示: 本次GC过程中 【所有线程】在内核态所消耗的时间总和
- real表示:本次GC过程中,实际GC消耗的时间
2019-5-1
数据库MVCC
- MVCC:多版本并发控制(Multi-Version Concurrency Control)
- 优势:查询速度快,并发环境尤是。对于大多数读操作,我们只需要通过MVCC进行简单的查询操作,而不需要获取任何一个
锁。- 劣势:需要多存储数据。对每一条记录都需要存储所有版本的数据
- MVCC只工作在REPEATABLE READ和READ COMMITED隔离级别下
- READ UNCOMMITED不是MVCC兼容:因为这个模式只能读取到最新的数据
- SERIABLABLE也不与MVCC兼容:因为每个读操作都需要为读到的数据上锁
MVVC机制:
- 以下摘自《五分钟搞清楚 MVCC 机制》
每一条数据库表记录,都隐藏2个字段
- 数据行的版本号 (DB_TRX_ID)
- 删除版本号 (DB_ROLL_PT)
执行insert语句插入的时候,会把当前的事务ID写到该记录的数据行的版本号 (DB_TRX_ID)中:
1
2
3begin;-- 获取到全局事务ID 假设为2
insert into `test_zq` (`id`, `test_id`) values('5','68');
commit;-- 提交事务id test_id DB_TRX_ID DB_ROLL_PT 5 68 2 NULL 6 78 1 3 修改数据库记录的时候
- 更新原记录的删除版本号 (DB_ROLL_PT)为当前事务ID
- 插入一行新的更新后的记录,且它的数据行的版本号 (DB_TRX_ID)为当前事务ID
1
2
3begin;-- 获取全局系统事务ID 假设为 10
update test_zq set test_id = 22 where id = 5;
commit;id test_id DB_TRX_ID DB_ROLL_PT 5 68 2 10 6 78 1 3 5 22 10 NULL 查询的时候需要根据
数据行的版本号 (DB_TRX_ID)和删除版本号 (DB_ROLL_PT)二者进行数据数据筛选,需要同时满足以下规则:数据行的版本号 (DB_TRX_ID)<= 当前事务删除版本号 (DB_ROLL_PT)> 当前事务
1
2
3begin;-- 假设拿到的系统事务ID为 10
select * from test_zq;
commit;id test_id DB_TRX_ID DB_ROLL_PT 6 22 10 NULL
2019-04-24
Spring的Lifecycle (SpringAppilication生命周期)
Spring会拿到所有Lifecycle实现类,然后委托DefaultLifecycleProcessor进行逐个处理
- Lifecycle 可以在SpringAppilication在初始化后执行start()方法,Spring停止的时候调用stop()方法
- 但是单单实现该类不能实现SpringAppilication在启动后,停止时调用Lifecycle对应的方法
- 这时候我们应该需要使用SmartLifecycle(Lifecycle的子类),重写isAutoStartup()返回true,才能产生理想效果
2019-04-23
关于测试类的规范
- 单元测试应该是不依赖于别的单元测试的
- 所有单元测试应该都得回滚,如果存在异步处理的情况,应尽可能把主线程与fork线程拆成2个测试类方法进行测试
- 每个测试类/测试方法应写上对应的名称@DisplayName
- 每个接口,都必须写一个正向测试方法
- 关于测试类的类名:测试类与被测试的类的路径需要一致,名字也需要对应,如:
1 | com.fpx.wms.service.impl.InstockServiceImpl |
- 关于测试类的方法名: 方法名尽可能为成功的条件如shouldSuccessAfterPay(),而方法具体用来测试哪个场景的,我们已经使用了@ DisplayName来描述,无须担心
- 对于结果,需要适应assert断言输出与结
2019-04-22
Spring @Lookup
作用
在单例A里 可能依赖到原型类型B,这时候如果用普通的Autowrite不能拿到原型的B,这时候就需要使用@Lockup了
使用参考
2019-04-21
架构设计三大原则
- 合适原则
- 简单原则
- 演化原则
即,合适优于先进,简单优于复杂,演化优于一步到位
→能不分,尽可能不分
2019-03-20
策略模式 vs 命令模式
1. 策略模式
1 | 策略模式针对一个命令,多种实现方式 |
2. 命令模式
1 | 命令模式针对多个命令,每种命令都有各自的实现 |
3. 总结
1 | 命令模式等于菜单中的复制,移动,压缩等,而策略模式是其中一个菜单的例如复制到不同算法实现。 |
2019-03-15
策略模式 vs 代理模式
1. 策略模式
1 | 需要调用方告知具体的策略 |
2. 代理模式
1 | 需要调用方告知使用哪个[代理类] |
2.1 动态代理
1 | 需要调用方告知[被代理类]及其接口 |
3.One More Thing
1 | 以上模式都需要客户端告知具体的[策略]/[代理]/[被代理者] |
2019-03-12
Spring循环依赖
场景现有3个类相互依赖,依赖关系分别为:
graph LR A-->B B-->C C-->A
场景细分为3种
- 构造注入参数循环依赖(报错)
报错
根据Spring初始化方式,Spring容器会按照顺序创建"无属性"的A放到“当前创建Bean池”中,同理再B、C、A,但是在再次创建A的时候发现“当前创建Bean池”已经存在A了,那么这时候会报错循环依赖
- Setter注入的循环依赖(
单例)
没毛病,在set的时候对象ABC都已经实例化放在Spring缓存了好了
- Setter注入的循环依赖(
prototype)
报错
prototype修饰的bean不会被Spring缓存,都是使用的时候当场创建的
Spring注入方式选择
结合上面的循环依赖问题,Setter出现问题的概率会低一些 推荐使用Setter注入
- 构造注入
- Setter注入
- 接口注入(没用过)
2019-03-11
一、集合操作
遍历
- Enumeration(JDK1.0)
- 只提供读集合相关功能,因为没有fail-fast,速度较快一点
- Iterator(推荐)
- 除了读功能,还有删除集合元素的能力,并且支持fail-fast(防止多线程同时对集合修改的一种机制)
修改
正例:
以List为例子,先得获取他的Iterator,通过iterator来进行修改操作
反例:
使用增强型foreach进行add/remove操作:
因为增强型foreach实际上是使用iterator实现的java语法糖:
1 | List<String> userNames = new ArrayList<String>() {{ |
编译后
1 | List<String> userNames = new ArrayList<String>() { |
1 | 所以实际上for (String userName : userNames) 这里每次都会去调用itertor.next() |
其它
fail-fast:
防止多线程同时对集合修改的一种机制
modCount:
****List**中的一个成员变量。它表示该集合实际被修改的次数
expectedModCount:
是 ****List**中的一个内部类——Itr中的成员变量
二、Hystrix
- Feign-starter包含Hystrix以及ribbon(只用他的均衡负载 http请求还是用feign自己的)
- 一个@FeignClient对应一个线程池或信号量
- 隔离
- 线程池隔离
tomcat的请求线程会交给线程池的线程处理
超过线程池会排队或者降级,一个线程池对应的服务挂了,不会影响别的线程池的服务- 信号量隔离
只作为开关
并发数超过X服务的信号量,多出来的Tomcat请求将会被拒绝
2019-03-09

2019-03-05
一、StringBuilder在高性能场景下的正确用法
StringBuilder在高性能场景下的正确用法(文中代码打错了一些字…)
- 正确写法应该是这样↓
StringBuilderUtil.java
2019-03-01
一、分布式锁
从需求上说,分布式锁要求是不一样的:
- 如果是用于聊天等社交场景,那么可以使用AP的分布式锁:Redis
- 如果是用于交易等不允许极端情况下获取锁不一致的,那么AP的Redis锁是不能接受的,这时候一定得用CP的分布式锁,如:etcd Zookeeper这一类
2019-02-22
一、ThreadLocal
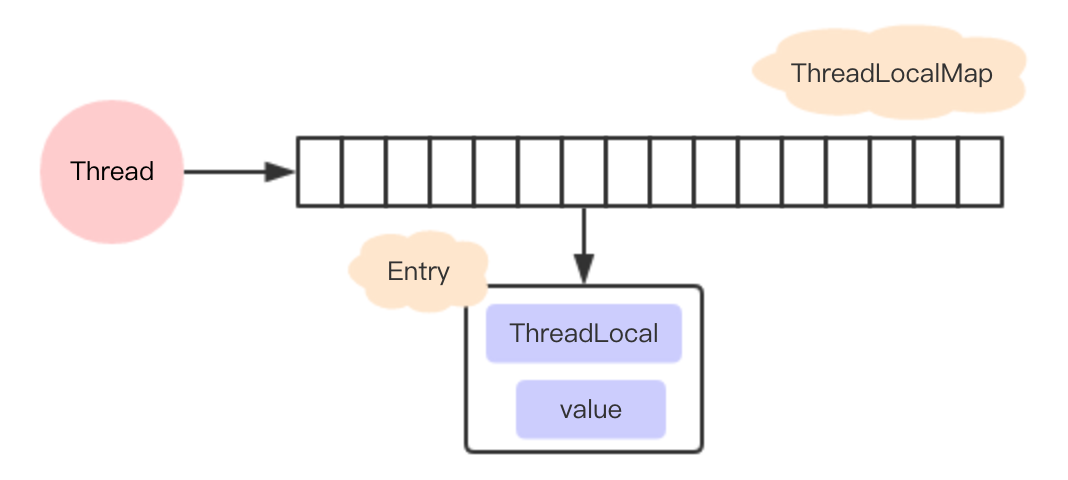
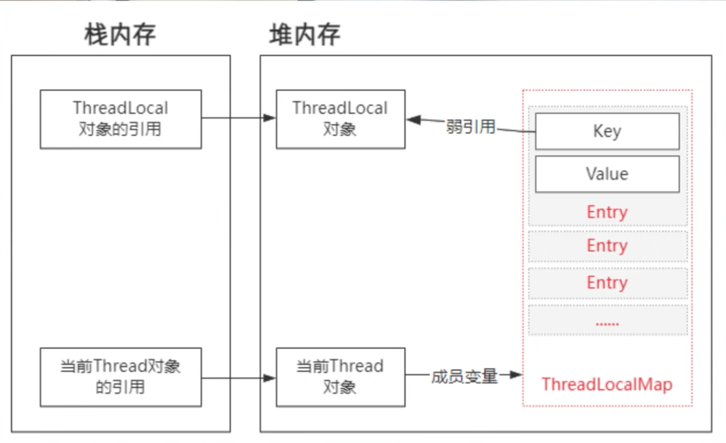
每个线程都有一个ThreadLocalMap,ThreadLocalMap以Entry的形式保存着各个线程自己的数据
Entry为一个WeakReference,以你new的ThreadLocal为Key
基于2.当你new的ThreadLocal没被外部强引用时,线程该Thread下对应该ThreadLocal的Entry会在下次GC被回收
当一条线程创建了多个ThreadLocal,多个ThreadLocal放入ThreadLocalMap 会极大地增加冲突概率
ThreadLocalMap对冲突的处理方式与普通HashMap的链表处理不一样,而是以原来的位置+1,一直寻找到没有冲突的地方存入
ThreadLocal在ThreadLocalMap中是以一个弱引用身份被Entry中的Key引用的
ThreadLocal.remove(),移除ThreadLocalMap与Entry的关系,释放内存
2019-02-17
一、常量池
常量池包含:
- class常量池 存在于class文件中
- 运行时常量池 存在于方法区中 一个类对应一个运行时常量池
- 字符串常量池 全局唯一 JDK6存在于方法区(独立于运行时常量池) JDK6以后存在于堆中
二、字符串加载到字符串常量池的2种方式
graph LR A[编译后的class文件中的class常量池] B[运行时常量池*N] C[字符串常量池] D[Java代码运行] A-->B D-->B B-->C
2019-01-28
Mybatis
一级缓存
(范围为一个SqlSession)
有Session/STATEMENT级别:
- 默认是SESSION 级别,即在一个MyBatis会
话中执行的所有语句,都会共享这一个缓存。 - 一种是STATEMENT 级别,可以理解为缓存只对当前执行的
这一个Statement 有效
二级缓存
基于mapper
二级缓存开启后,同一个namespace下的所有操作语句,都影响着同一个Cache,即二级缓存被多个SqlSession共享
- 补充: 缓存为本地缓存, 在集群部署的系统里开启后,会导致A1查询与A2查询结果不一致的问题 看情况开启,一般为关闭;或者使用Redis等工具使用统一的第三方缓存
2018-11-06
一、 分布式事物要看场景的
举个例子:
- 流量充值涉及到订单支付,金钱交易严格用tcc;
- 订单支付完后要给用户增加积分,这个必要成功,用最终消息一致性方案;
- 订单支付完后还要给用户发送一条短信,短信一般是跟电信运营商的第三方接口对接,有可能成功有可能失败,用最大努力通知方案
2018-11-06
一、JVM逃逸分析与TLAB(Thread Local Allocation Buffer)
启动逃逸分析后,会分析没有逃逸的对象,把没有逃逸的对象分配在线程私有的栈里,性能提高5倍
TLAB(默认开启)存在于新生代,默认占其1%,为线程私有;因为线程私有,没有锁开销(对象分配的时候不需要锁住整个堆),效率高;
创建对象时内存分配流程:
- 逃逸分析,确定分配在哪,如果是分配在堆则2
- 尽量分配在当前线程的TLAB,不够就去再申请一个TLAB,还不够则3
- 加锁Eden区,在Eden申请内存,不够则4,
- 执行Young GC
- Young GC后,如果还不够,放入老年代
对象分配流程写的不错
参考:https://blog.csdn.net/yangzl2008/article/details/43202969
2018-10-19
一、Feign Consul 获取可用服务IP
- HealthConsulClient.getHealthServices获取可用IP
通过http://consul.uat.i4px.com:8500/v1/health/service/pds-pos-outer?token=
最终会在ConsulServerUtils.findHost()得到服务所对应的可用IP
IP获取逻辑是:
- 获取Service.Address字段作为可用IP
- 取不到就取Node.Address
二、Consul
1.服务注销/删除
http://consul.uat.i4px.com:8500/v1/agent/service/deregister/fpx-prs-service-10-104-5-15-8002
2.查看可用服务
http://consul.uat.i4px.com:8500/v1/health/service/wims?passing=true
2018-10-18
一、多服务的【事务】阻塞(跨机器)
- 数据库锁分为读锁、写锁,读读共享,写写互斥,读写互斥
- 程序A正在开启事务,操作(包括CRUD) 数据库记录A时,A会被行级锁(读/写锁);
- 其它程序若要对进行互斥锁操作,需要阻塞到该锁被释放(程序A提交事务),
2018-09-29
一、接口返回的JSON数据,快速转换为实际数据
ObjectMapper mapper = new ObjectMapper();
SimsPudo simsPudo = mapper.convertValue(responseMessage.getData(), SimsPudo.class);
2018-09-29
一、-XX:+PrintFlagsFinal
:=意味着值是被修改的, =表示默认值
2018-09-29
一、Feign重试
- 默认只会对connect timeout进行重试
- OKToRetryOnAllOperations=true
- 会对connect timeout和socket read timeout都进行重试,对socket read timeout会引起后端重复处理请求问题(需要做幂等)
- Feign对于>400的后端报错是不会重试的
- 设置了OKToRetryOnAllOperations=true所有后端需要幂等
OKToRetryOnAllOperations=false的前端需要做对应的超时异常处理,如:
i.写代码自动重试
ii.直接返回前台成功
二、超时时间
- (socket)connect timeout 连接超时
- (socket)read timeout 读超时
对read timout,请求已经到达后端处理,但是没在指定时间内返回
三、Http状态码分类
- 1XX:正在处理
- 2XX:请求处理成功
- 3XX:请求需要重定向
- 4XX:服务器无法处理请求(U Fuck Off)
- 5XX:服务器处理请求出错(I Fuck Off)
四、String
- “ABC”:
是显示声明的 以"ABC"形式存在于常量池中(常量池也在堆里)- new String(“ABC”):
以对象形式存在于堆中- str.intern(),字符串(或引用)是否存在于常量池,不存在就把该引用存在常量池
- “ABC”.intern() 没意思,本来就是放在常量池的东西,再调intern没用
五、@Transaction
- @Transactional方法会覆盖类上的配置
- 调用被注入的代理类才能有效地激活@Transaction的效果
2018-09-28
一、JVM参数配置
-XX:+PrintCommandLineFlags
打印改动过的JVM参数
-XX:+PrintFlagsFinal打印最终在用的参数
-XX:+UnlockExperimentalVMOptions
-XX:+UnlockDiagnosticVMOptions
显示隐藏参数
二、Feign前后端全局异常处理
- 后端【业务代码直接抛异常】
- 后端全局异常捕获时【返回带异常信息的ResponseMsg】(一般不含堆栈信息),同时返回状态码设置为500(也可以404,因为Feign默认后端报错就是返回404)
- 前端(调用者)ErrorDecode时,解析该[ResponseMsg的异常信息],重新throw对应的异常就能保证前后端异常一致了
- [x] 对于需要进入fallback的调用
同上处理,但是按需可能需要使用FallbackFactory获取后端返回的异常信息进一步处理 如打印日志等
- [ ] 问题:可能导致前端(调用方)不能切换实例重试
- [ ] 加入Decode404=true后,404错误不会进入ErrorDecode和Fallback
2018-09-17
一、正确的kill进程
先kill -15(安全关闭 回收资源)
不行再kill -9(强制关闭)
2018-09-16
一、JDK8+移除了Perm
jdk8移除了Perm
其方法区及常量池等数据,全部移到了元数据区(Metaspace)中
二、String.intern
JDK7及以后版本,是复制其字符串引用到常量池中
实际数据还是存在于堆中
二、-XX:MetaspaceSize
-XX:MetaspaceSize=200m不是初始元空间大小,而是达到了200m后才会对该区域进行GC
2018-09-06
一、获取全局唯一ID
- redis: 服务器时间戳+redis全局自增id=>UUID
简单、快捷- zk:同上
比较慢- 通过数据库
慢、并发低- twitter的雪花算法: 通过时间戳+机器ID=>UUID
优势:速度快、无需依赖中间件、全局唯一
2018-09-05
一、SQL的强制索引
select * from parcel FORCE INDEX(uniq_fpx_tracking_no_1) where fpx_tracking_no not in (‘901000486441’,‘901000497454’) ;
二、接口幂等理解
分布式锁实现幂等的方式
- 查询缓存结果,存在就返回
- 不存在,获取分布式锁(阻塞等待)
- 再尝试第一步(其实就是双重校验)
- 不存在,开始执行业务逻辑,并且缓存结果
- 释放锁
分布式锁实现的幂等,不完全可靠,因为缓存会过期
- 要保证其绝对可靠,还是得使用select+insert、唯一索引等方式
三、IO多路复用模型
https://mp.weixin.qq.com/s/xmSn9Xz6MiFb2s_0J7iXwQ
- 单Reactor单线程(Redis)
- 单Reactor多线程
- 多Reactor多线程(包括 Nginx 主从 Reactor 多进程模型,Memcached 主从多线程,Netty 主从多线程模型的支持)
- 单 Reactor 单线程,接待员、侍应生、后厨是同一个人,全程为顾客服务
- 单 Reactor 多线程,1个接待员,多个后厨
- 主从 Reactor 多线程,1个接待员,多个侍应生,多个后厨