
常见查找算法应用总结2
接: 常见排序算法应用总结
前言
其实多算法涉及不是很深,也不打算在使用前深究,究了没多久就忘了纯属浪费时间。这里做下记录,日后用到直接来这里找就完事啦~~
常见搜索算法及其特点
1. 线性搜索(Linear Search)
- 时间复杂度:最好情况 O(1),最坏情况 O(n)
- 使用场景:适用于数据规模较小,或者数据分布随机的情况
- 优势:实现简单易懂
- 缺点:效率较低,不适用于大规模数据的搜索
- 具体案例:在一个由数值大小不一的小数组中查找特定的数值,例如在一个长度为 10 的数组中查找数值 5
2. 二分搜索(Binary Search)
- 时间复杂度:O(log n)
- 使用场景:适用于数据已排序的情况
- 优势:效率较高,适用于大规模数据的搜索
- 缺点:需要数据已排序,实现较为复杂
- 具体案例:在一个由数值大小递增的大数组中查找特定的数值,例如在一个长度为 10000 的数组中查找数值 5000
3. 插值搜索(Interpolation Search)
- 时间复杂度:最好情况 O(1),最坏情况 O(n)
- 使用场景:适用于数据有序且分布均匀的情况
- 优势:效率较高,比二分搜索更快,适用于大规模数据的搜索
- 缺点:数据分布不均匀时效率会变得很低
- 具体案例:在一个由数值大小递增的大数组中查找特定的数值,例如在一个长度为 10000 的数组中查找数值 5000
4. 哈希表(Hash Table)
- 时间复杂度:最好情况 O(1),最坏情况 O(n)
- 使用场景:适用于数据随机分布的情况
- 优势:效率较高,适用于大规模数据的搜索
- 缺点:需要占用较大的内存空间,实现较为复杂
- 具体案例:在一个由随机数值构成的大数组中查找特定的数值,例如在一个长度为 10000 的数组中查找数值 5000
5. 广度优先搜索(Breadth-First Search,BFS)
- 时间复杂度:O(V+E),其中 V 表示节点数量,E 表示边数量
- 使用场景:适用于无权图或者权值较小的图的搜索
- 优势:能够找到最短路径,实现简单易懂
- 缺点:占用内存空间较大,不适用于权值较大的图
- 具体案例:在一个无向图中查找从起点到终点的最短路径,例如在一个迷宫中查找从起点到终点的最短路径
6. 深度优先搜索(Depth-First Search,DFS)
- 时间复杂度:O(V+E),其中 V 表示节点数量,E 表示边数量
- 使用场景:适用于遍历图、寻找所有路径的情况
- 优势:实现简单易懂
- 缺点:不保证找到最短路径,可能陷入死循环
- 具体案例:在一个由数个节点构成的地图中查找从 A 到 B 的所有路径
7. A* 算法(A-star Algorithm)
- 时间复杂度:最好情况 O(1),最坏情况 O(b^d),其中 b 表示每个节点的平均分支数,d 表示起点到终点的最短距离
- 使用场景:适用于有权图的最短路径搜索
- 优势:在广度优先搜索和启发式搜索的基础上,引入估价函数,实现了更高效的搜索
- 缺点:需要事先知道起点和终点的位置,实现较为复杂
- 具体案例:在一个由数个节点和边权值构成的地图中查找从 A 到 B 的最短路径
8. 二叉搜索树(Binary Search Tree,BST)
- 时间复杂度:平均情况 O(log n),最坏情况 O(n),其中 n 表示节点数量
- 使用场景:适用于有序数据的搜索,或者需要维护数据有序性的情况
- 优势:效率较高,实现简单易懂,能够维护数据有序性
- 缺点:极端情况下会退化成链表,影响搜索效率
- 具体案例:在一个由数值大小递增的大数组中构建二叉搜索树,进行数据搜索。
不同的算法适用于不同的场景。在选择搜索算法时,需要综合考虑数据规模、数据分布、搜索目标等因素,并选择适合的算法进行应用
同时,在实际应用中,还可以结合具体场景,选择合适的算法进行优化,例如:
在一个大规模数据的搜索中,可以通过使用哈希表或者二分搜索等高效算法来提升搜索效率
在寻找最短路径的场景中,可以使用 A* 算法或者广度优先搜索来找到最优解。在数据有序性较强的场景中,可以使用二叉搜索树来维护数据有序性并进行快速搜索
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 花火笔记!
相关推荐
2018-04-19
常见排序算法应用总结
前言 其实多算法涉及不是很深,也不打算在使用前深究,究了没多久就忘了纯属浪费时间。这里做下记录,日后用到直接来这里找就完事啦~~ 常见排序算法时间: 1. 冒泡排序(Bubble Sort) 时间复杂度:最好情况 O(n),最坏情况 O(n^2) 空间复杂度:O(1) 使用场景:适用于数据规模较小的情况,且数据分布情况不明显 优势:实现简单易懂 缺点:效率较低,不适用于大规模数据的排序 具体案例:对于一个由数值大小不一的小数组进行排序,例如对一个长度为 10 的数组进行排序 2. 选择排序(Selection Sort) 时间复杂度:最好情况 O(n^2),最坏情况 O(n^2) 空间复杂度:O(1) 使用场景:适用于数据规模较小的情况 优势:实现简单易懂 缺点:效率较低,不适用于大规模数据的排序 具体案例:对于一个由数值大小不一的小数组进行排序,例如对一个长度为 10 的数组进行排序 3. 插入排序(Insertion Sort) 时间复杂度:最好情况 O(n),最坏情况 O(n^2) 空间复杂度:O(1) 使用场景:适用于数据基本有序的情况,或者数据...
2017-04-19
HashMap-JDK1.8
参考链接:HashMap在JDK1.8之前和之后的区别 JDK1.8之前 new HashMap(n)中的n为其容量 元素插入使用头插法 并发插入(resize时)会产生循环链表,在get一个不存在的元素时会导致死循环。参考:Java HashMap的死循环 JDK1.8之后 元素使用尾插法 new HashMap(n)中的n最接近的2^m为其容量 并发插入还是有问题,但不会产生死循环 插入时数组长度>64,桶元素>8时,会树型化 发生resize时,resize后,桶元素个数<=6的,都会被解树型化 取模用与操作(hash & (arrayLength-1))会比较快,所以数组的大小永远是2的N次方。你随便给一个初始值比如17会转为32 resize实现逻辑参考:Java HashMap工作原理及实现 HashMap关于static final int UNTREEIFY_THRESHOLD = 6的分析 遍历整个原始桶,把桶内数据分配到原桶与新桶中 具体图解分析可以参考以下链接的第六点:Java HashMap工作原理及实现 判断新桶元...
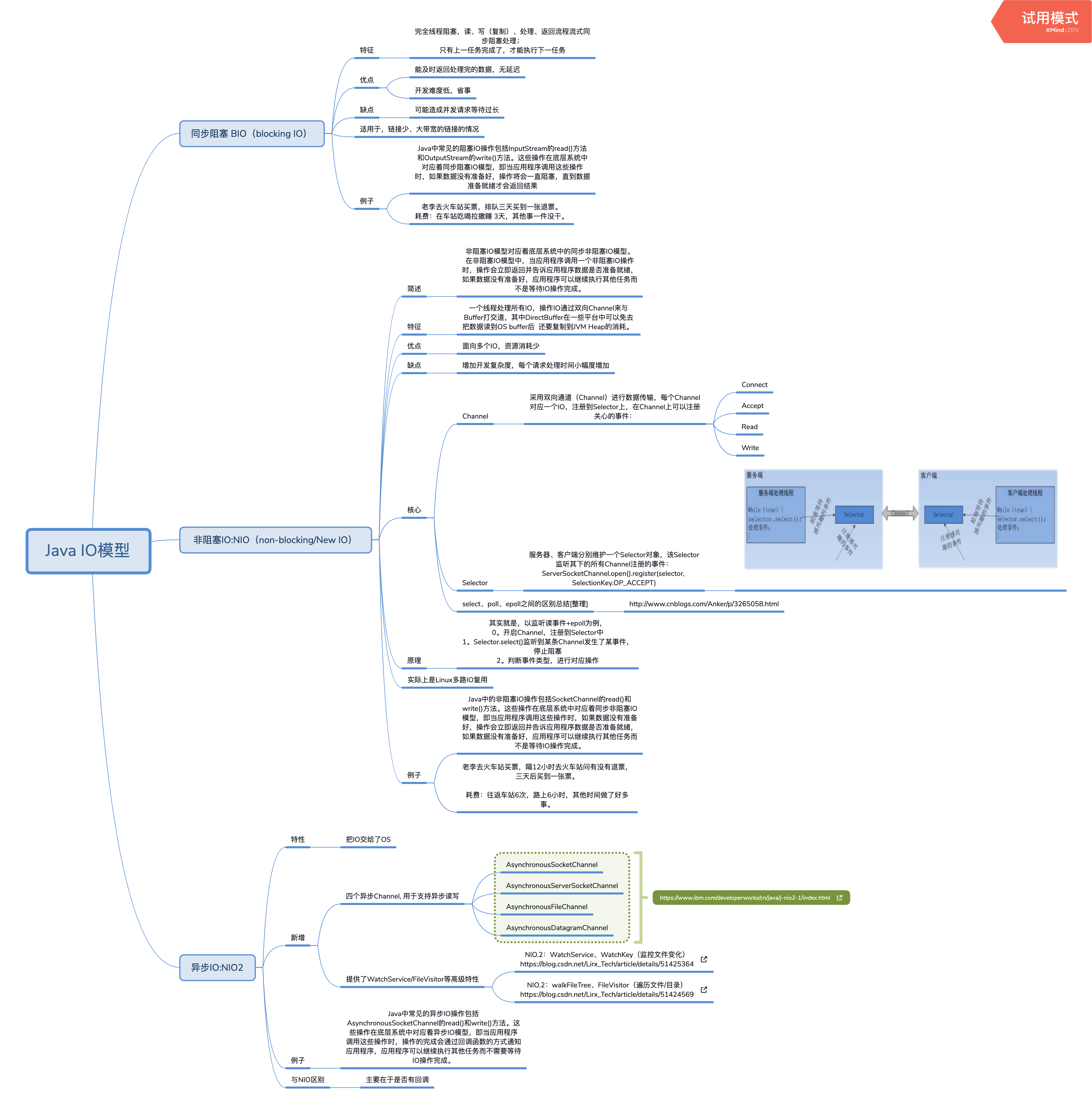
2020-10-03
IO模型
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/system/IO-model.html 背景 服务器网络模型 这篇IO模型是《每天进步一点点》里的第一篇学习记录,真的是忘了看看了忘了。。其实不用记服务器的,大概理一下JAVA自己的就简单多了,这里稍微总结一下: JAVA IO模型 JAVA的IO模型分为BIO、NIO、AIO三种,其中BIO是阻塞IO,NIO是非阻塞IO,AIO是异步IO 阻塞IO模型: Java中常见的阻塞IO操作包括InputStream的read()方法和OutputStream的write()方法。这些操作在底层系统中对应着同步阻塞IO模型,即当应用程序调用这些操作时,如果数据没有准备好,操作将会一直阻塞,直到数据准备就绪才会返回结果。 非阻塞IO模型: Java中的非阻塞IO操作包括SocketChannel的read()和write()方法。这些操作在底层系统中对应着同步非阻塞IO模型,即当应用程序调用这些操作时,如果数据没有准备好,操作会立即返回并告诉应用程序数据是否准备就绪,如果数...
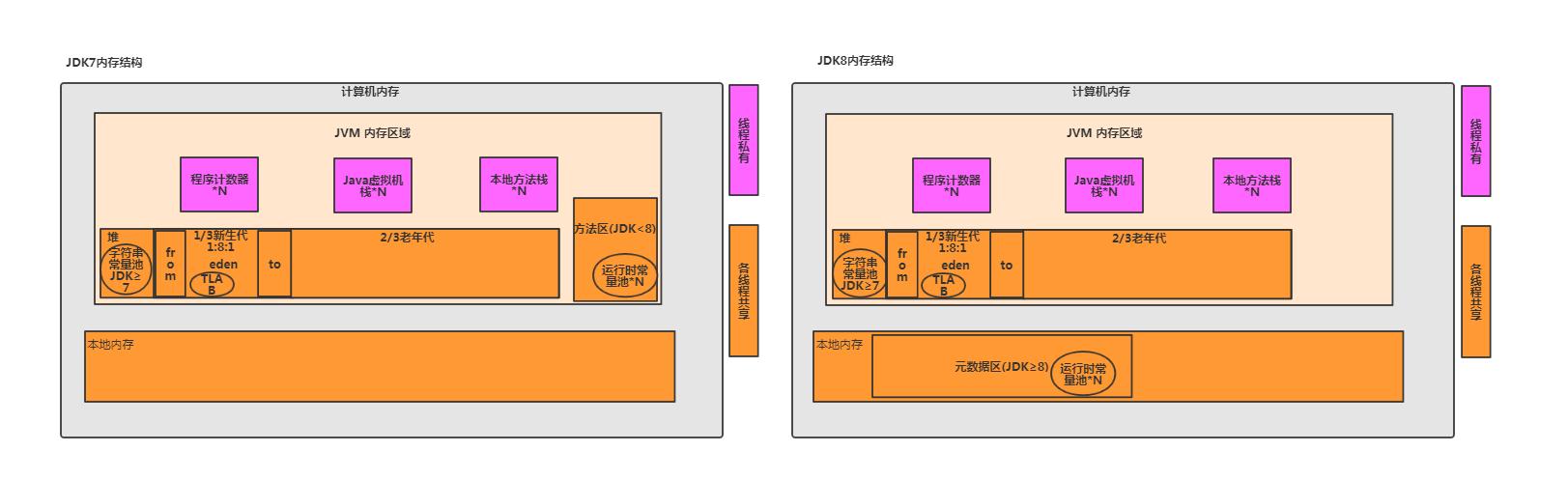
2019-02-16
JVM内存结构-总纲
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/JVM/JVM-Memory-Structure-Menu.html 学习JVM的可以去我的GitHub 上查看我的Xmind详细笔记 对整本《深入理解JVM》都有详尽的笔记,帮助理解 前言 网上有不少描述JVM内存结构的文章,但是要么比较老久了,要么描述有误,今天根据自己的理解整理下,有误请指正。 整体图解 程序计数器 记录Java程序运行到哪里 线程私有,可以看做当前线程执行到哪行【字节码】 字节码解析器工作就是通过改变这个【计数器】来选择下一行要执行什么,分支、循环、线程恢复都依赖于它 若为Java方法,则记录当前执行的字节码指令地址; 若执行的是native方法,则为空 Java 虚拟机栈 描述java【方法】执行的【内存模型】 每个方法对应一个栈帧,在线程运行到该方法时才创建 一条线程拥有的栈帧之和最大为-Xss(我们这里把它叫做线程栈) 当前所有线程栈之和=当前Java虚拟机栈已用大小 Java虚拟机栈总空间最大值:JVM...
2021-08-11
垃圾回收器选型
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/JVM/jvm-gc.html 总揽 吞吐量和最短停顿时间本来就互相矛盾 Parallel Old追求的是吞吐量,CMS追求的是STW的最短 而G1通过把堆分成多个相对独立的Region块,并行的进行选择性的回收,实现一个两者兼顾的回收器 Parallel GC: 适用于吞吐量优先的场景 原理: 通过参数-XX:GCTimeRatio 设置垃圾回收时间占总时间的比例,默认值为99,即垃圾回收时间不超过1%,实现吞吐量优先 CMS(Concurrent Mark Sweep)GC: 适用于响应时间优先的场景 原理1:通过-XX:CMSInitiatingOccupancyFraction预留空间实现一边回收垃圾,一边执行业务逻辑,实现响应时间优先 原理2:通过并发标记等,实现尽可能低的停顿 缺点1: 内存使用率低,为了一边干活一边回收垃圾,预留了一定的内存 缺点2:产生碎片,虽然FullGC时候,但是运行期间会产生大量碎片 (新增)G1(Garbage...
2022-05-04
生产故障分析:线程池配置错误导致的阻塞问题
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/SA/Solution/Production-Issue-ThreadPool-Misconfiguration.html 问题背景
