
dubbo调用流程
[半转载]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/dubbo/dubbo-call-flow.html
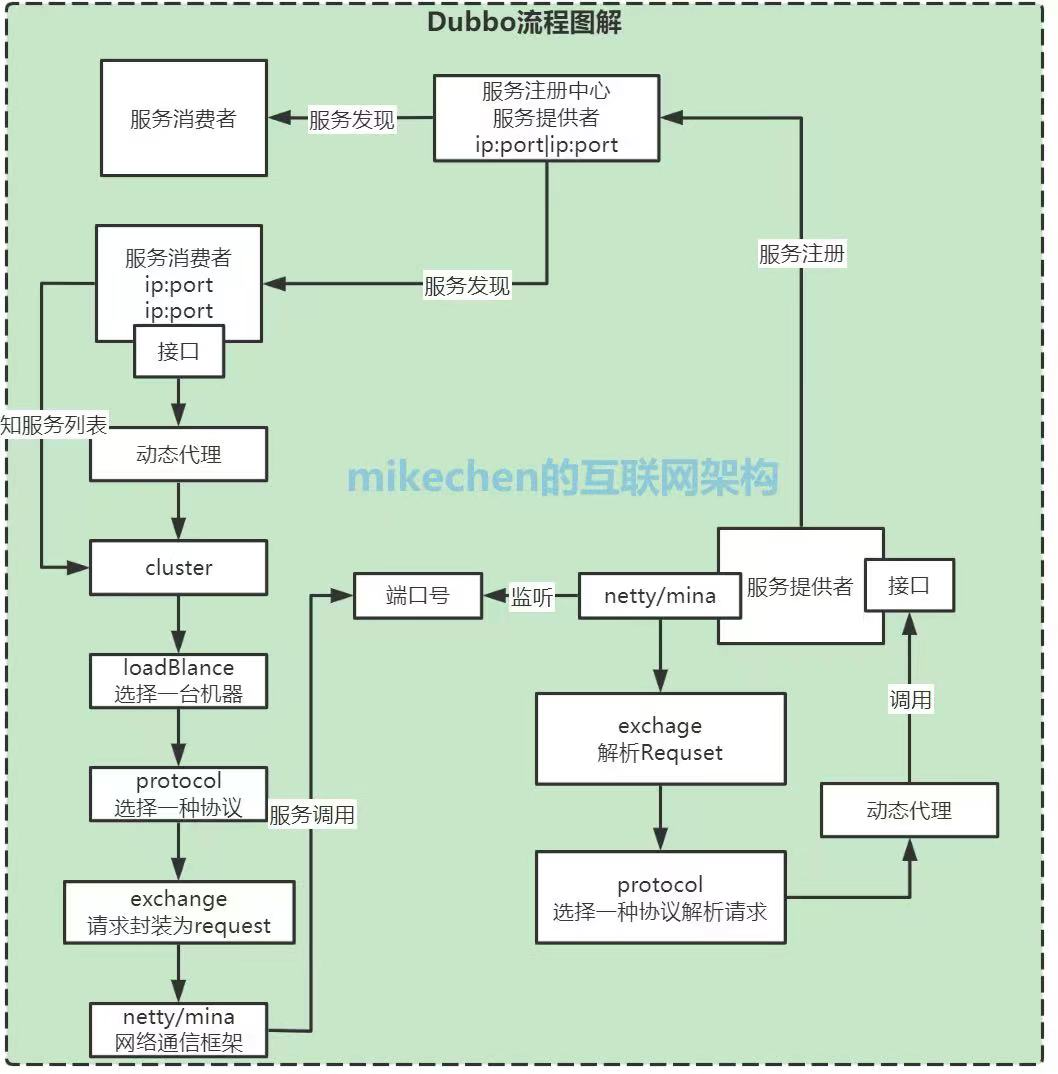
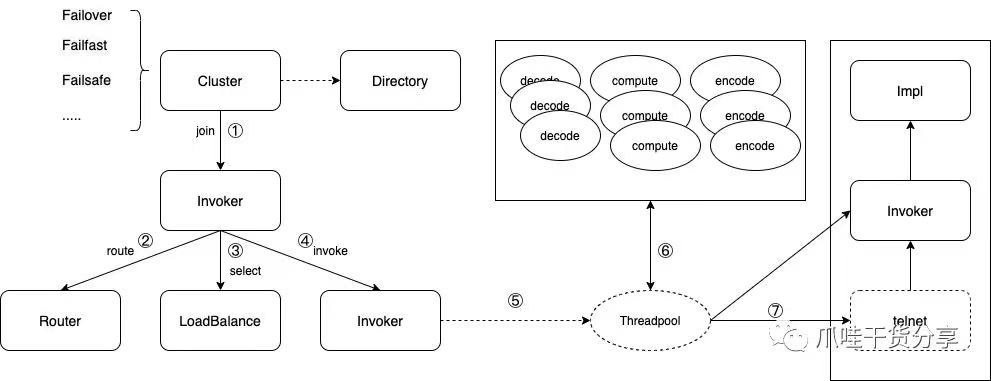
概要精简版流程
- 客户端从注册中心拉取和订阅服务列表
- 聚合服务列表,形成Invoker
- 客户端通过路由和负载均衡选择合适的服务提供者
- 将请求交给底层的I/O线程池处理
- 在I/O线程池中进行序列化和反序列化等操作
- 将请求交给业务线程池处理业务方法调用
Dubbo的调用流程主要在客户端完成,通过注册中心、路由、负载均衡等机制实现服务的发现和选择,然后通过底层的I/O线程池和业务线程池处理请求。这样的设计使得Dubbo具备高性能、高并发的特点,适用于分布式系统中的服务调用场景。
补充版流程
客户端启动时,会从注册中心拉取并订阅对应的服务列表。这些服务列表会被聚合成一个Invoker(调用器)。Cluster模块会将多个服务提供者聚合成一个Invoker。
在发起RPC调用之前,客户端会通过Directory#list方法获取服务提供者的地址列表,这些地址列表将被用于后续的路由和负载均衡操作。Dubbo内部还有一个实现了Directory接口的RegistryDirectory类,它和接口名是一对一的关系,负责拉取和订阅服务提供者、动态配置和路由项。
在Dubbo发起服务调用时,所有的路由和负载均衡操作都是在客户端进行的。首先会触发路由操作,然后将路由结果得到的服务列表作为负载均衡的参数。经过负载均衡算法的选择,将选出一台合适的机器进行RPC调用。
客户端经过路由和负载均衡后,将请求交给底层的I/O线程池(比如Netty)进行处理。I/O线程池主要负责处理读写、序列化和反序列化等操作。在这个阶段,必须避免阻塞操作,Dubbo提供了相应的参数控制。在处理反序列化对象时,可以选择在业务线程池中进行处理。
在整个流程中,涉及到两种线程池。一种是I/O线程池(比如Netty),主要负责底层的I/O操作。另一种是Dubbo业务线程池(Dubbo线程池):Dubbo还提供了一个业务线程池,用于承载业务方法的调用。在处理完底层的I/O操作后,Dubbo将请求交给业务线程池处理。这样可以避免阻塞I/O线程,提高系统的并发处理能力。
dubbo的多线程并发调用如何正确响应对应的线程(类似http2连接复用原理)
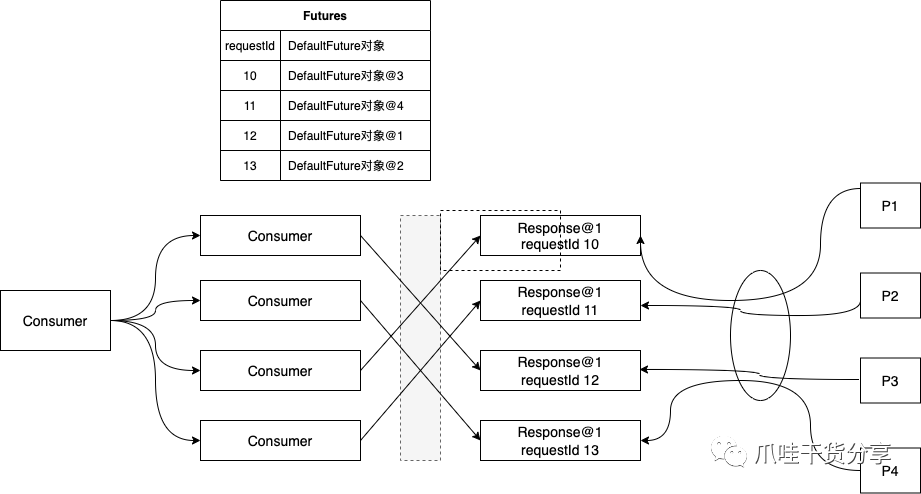
- 当客户端多个线程并发请求时,框架内部会调用DefaultFuture对象的get方法进行等待
- 在请求发起时,框架内部会创建Request对象,这个时候会被分配一个唯一 id, DefaultFuture 可以从Request对象中获取id,并将关联关系存储到静态HashMap中,就是上图中的Futures 集合
- 当客户端收到响应时,会根据Response对象中的id,从Futures集合中查找对应 DefaultFuture对象,最终会唤醒对应的线程并通知结果
- 同时客户端也会启动一个定时扫描线程去 探测超时没有返回的请求
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 花火笔记!
相关推荐
2099-09-05
每天进步一点点 - 基础技术篇
[原创]这篇只是做点记录备忘,个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Make-A-Little-Progress-Every-Day/Make-A-Little-Progress-Every-Day-Basic-Technology.html 本文不怎么更新了 2022-10-25 目前本地缓存使用的方式 订运单系统: SF自研的类Ehcache框架,存储的内容不是特别多,都是一些网点月结卡号信息,所有对象存在于Map,占200m左右 SISP系统: 使用了Caffeine,存储的内容,存储的内容很多,包括员工表(900m),人员表(bdus 800m) 客户表(1.2g),用户及权限相关表(500m) 关联后约占4g内存,目前采用Caffeine默认存储方式,启动即全量加载(极个别采用懒加载方式加载),全部存在于Map中,即堆存储 优化: 缓存为基础数据,数据量稳定,目前采用CMS回收器,堆空间8g,缓存存于堆中,占约4g,平时MajorGC达4~6s,曾出现高峰gc达52s, 应考虑将缓存存于堆外...
2019-05-22
【Spring源码分析】循环依赖的处理
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Spring/Spring-Circular-Dependencies.html 看源码的同学可以查看我的GitHub 上面在官方的基础上加入了大量中文注释,帮助理解 要了解的知识 什么是循环依赖 graph LR A-->B B-->C C-->A 存在哪些循环依赖 Setter循环依赖(可以被解决) 构造循环依赖(报错) 基于Prototype类型的循环依赖(报错) Bean的创建步骤 看源码的同学可以找到源码: 环节1~4的代码在AbstractAutowireCapableBeanFactory#doCreateBean方法中 环节5的代码在DefaultSingletonBeanRegistry#getSingleton(String,ObjectFactory)方法的addSingleton(beanName, singletonObject);中 Spring是怎么处理循环依赖的(对于单例Bean) 实现原理 Spring在创建...
2019-12-12
Spring常见事件
[转载]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Spring/Spring-events.html ContextRefreshedEvent:表示ApplicationContext已经初始化或刷新完成时触发。通常在应用程序启动时使用,用来执行初始化操作 ContextStartedEvent:表示ApplicationContext已经启动时触发。通常在应用程序启动时使用,用来执行一些启动任务 ContextStoppedEvent:表示ApplicationContext已经停止时触发。通常在应用程序停止时使用,用来执行一些清理任务 ContextClosedEvent:表示ApplicationContext已经关闭时触发。通常在应用程序关闭时使用,用来执行一些清理任务 RequestHandledEvent:表示Web请求已经处理完成时触发。通常在Web应用程序中使用,用来记录日志或统计数据 ApplicationStartedEvent:表示Spring Boot应用程序已经启动完成时触发。通常在Spri...

2099-12-05
每天进步一点点 - English
[原创]这篇只是做点个人英语学习的记录,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Make-A-Little-Progress-Every-Day/Make-A-Little-Progress-Every-Day-English.html 2025-12-11 Vocabulary Sentence - conversation Just updating is enough. (只要更新就够了) I call handle it all by myself, expect business matters. (我自己处理所有事情,除了商务事务) I am swamped. (我忙得不可开交) Sentence - email I am here to assist you with anything you need. (我在这里协助你处理任何你需要的事情) I am writing to inform you that… (我写信是为了通知你…) Please let me know if you have any qu...
2019-05-22
Spring白板源码整理
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Spring/Spring-whiteboard.html 这本经常出错的辣鸡书的读后整理:《Spring源码深度解析》 仅记录,日后有空加描述,嗯,有空的话,有空再说。。。 SpringAOP源码 Spring事务源码 SpringMVC Spring DispatcherServlet源码 Spring+Mybatis整合原理源码分析 Spring整合MyBatis的原理是将MyBatis的SqlSessionFactory和Spring的IoC容器进行集成,从而在Spring容器中管理SqlSessionFactory对象,进而管理MyBatis的SqlSession对象 在Spring整合MyBatis的过程中,主要用到了以下几个FactoryBean: SqlSessionFactoryBean: 它是一个FactoryBean,用于创建SqlSessionFactory对象,并将其纳入Spring容器进行管理。它通过配置DataSource等参数,...

2019-01-09
MQ常见问题及其处理方案
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/MQ/mq-common-problem.html 基于Rabbitmq: