
通用kafka延迟队列生产实践
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/general-kafka-delay-queue.html
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 花火笔记!
相关推荐
2019-12-31
Kafka延时队列方案探讨
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/Kafka-Delay-Queue.html 目前在用方案:直接重新丢回队列后面 实现逻辑 引入延迟消息消费服务,消费延迟消息 每条消息消费时,Sleep3秒(很长),再处理; 处理时判断是否到点,没到点的数据丢回kafka 优点 不引入新依赖(不依赖DB,不依赖其他第三方) 缺点 1. 处理效率慢,并发低 2. 延时时间不精准,颗粒度非常大 3. 浪费Kafka空间,同一数据在Kafka多次存储(其实Kafka底层是一种文件/文档存储,消息的消费只读不删) 优化方案1: 延迟消息存DB,通过Redis的zset结构支持 ### 实现逻辑 #### 1. 发送延时消息: > 延时消息发送到延时队列TopicA ### 2. 消费延时消息: > 延时程序(消费者)消费延迟队列的消息,把延时消息存入DB,再把[发送时间]+[延时消息在DB记录ID]作为zset设到Redis ### 3. 监控&&发送[到时的消息]: > 1....
2025-12-15
精准定时任务设计思路
type: drafts [原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/precise-timing-task-design.html 这里主要是以订单超时取消为例 粗略记录,日后完善 取消任务先加入数据库(持久化存储),后加入当前节点时间轮(本地内存) 通过时间轮任务,触发订单取消逻辑、同时把数据库的任务删除 节点重启后,先通过数据库加载属于自己节点的任务到本地时间轮 注意,此处存在一些已经超时的任务,需要加载的时候顺便执行取消订单逻辑,把过期的任务从数据库删除 节点的时间轮恢复,后续继续通过1. 2. 步骤继续运行
2023-05-02
缓存强一致性方案
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/cache-consistency-solution.html 背景 考虑到部分场景可能需要强一致性缓存: 后端更新时,需要保证使用端查询缓存时立马就能查询出最新的缓存值,且需要考虑并发场景导致的不一致情况 所谓的『强一致性』问题确认 首先,确认的是,我们讨论的一致性问题不是最终一致性这种,而是强一致性,前者可以通过数据库消费binlog设置缓存的形式实现,后者则需要考虑并发场景下的问题 方案设计–基于类似分布式锁实现 在后端更新数据库前,先将缓存值设置为『LOCK』,并设置一个过期时间,这个过期时间需要根据业务场景来设置,一般来说,这个过期时间需要大于后端更新缓存的时间,这样可以保证在后端更新缓存时,缓存值一直是『LOCK』状态 后端更新数据库、提交事务后,再将缓存值设置为『正常值』,这样就可以保证缓存值一直是『LOCK』状态 用户侧使用缓存前时先判断缓存值不为『LOCK』,为『LOCK』则阻塞等待更新完成,否则直接使用缓存值 至此,就可以保证缓存的...
2021-05-02
生产数据库扩库
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/database-scale.html 背景
2021-03-02
记一次ES查询优化
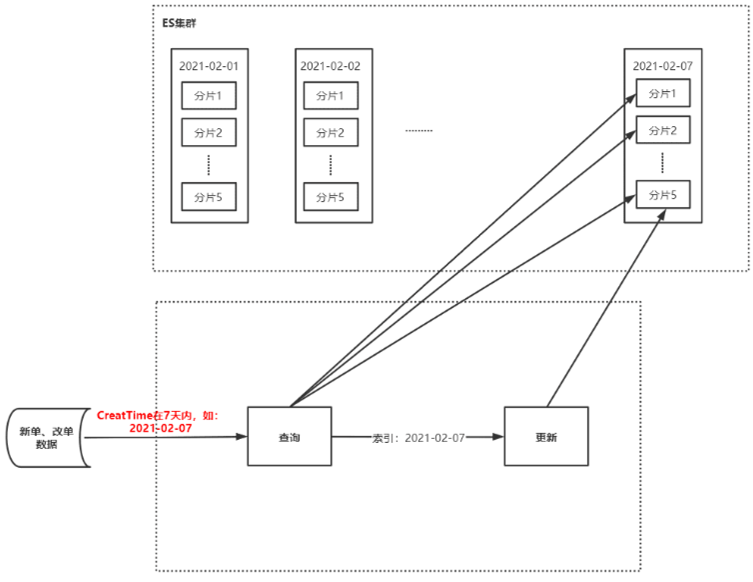
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/ES-Query-Optimization.html 背景 难得有数据留存,写一篇^_^ 原逻辑 ES接收新单、改单、状态数据(占总数据的70%),写入ES的7天索引中 ES存在以天为单位的7个索引(如:20210101~20210107,7个索引) 存储逻辑: 根据订单创建时间,保存到对应月日的索引内,如:1月1日的保存到20210101 如果不再最近7天内的特殊订单,那么会存到今天最新的一天的索引内 查询查询: 接收到查单请求后,根据订单创建时间,根据月日指定去查询这7个索引的某一个或多个 如果是在最近7天的,那么保存到该日期对应的索引内 如果在最近7天以外的订单,那么会保存到今天最新的一天的索引内 更新逻辑: 先查询出原来的订单,然后更新,更新后保存到原来的索引内 初步分析 监控问题分析 大数据监控显示:在双十一前后ES监控IO读写次数过高,出现读/写拒绝,CPU占用高,初步分析主要原因有以下: 量大:写入ES的数据...
2020-08-12
秒杀架构设计
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/framework-design/sec-kill-framework-design.html 常见的三类高并发场景 高并发压力主要来自,并发时出现大量锁冲突 1.细颗粒度操作-锁冲突少 如:QQ微信等即时通讯业务个人读个人自己的数据 数据结构 个人信息 user(uid…) 几十亿 个人的好友信息 friend(uid,friend_id…) 几百亿 个人的群 user_group(uid,group_id…) 几百亿 群成员 group_member(gid,uid…) 几千亿 个人消息(msg_id,uid…) 几千亿 群消息(msg_id,gid…) 几千亿 个人和群都是读写自己的数据 在高并发时(单个用户单位时间发出N个读写请求),锁冲突极小,每个【人】、【群】、【消息】只会锁住自己部分的消息 在出现IO瓶颈的时候 只需要进行水平分库 把【人】、【群】、【消息】进行切分 2.读多写少,存在少量写冲突 如:微博 自己的...
