
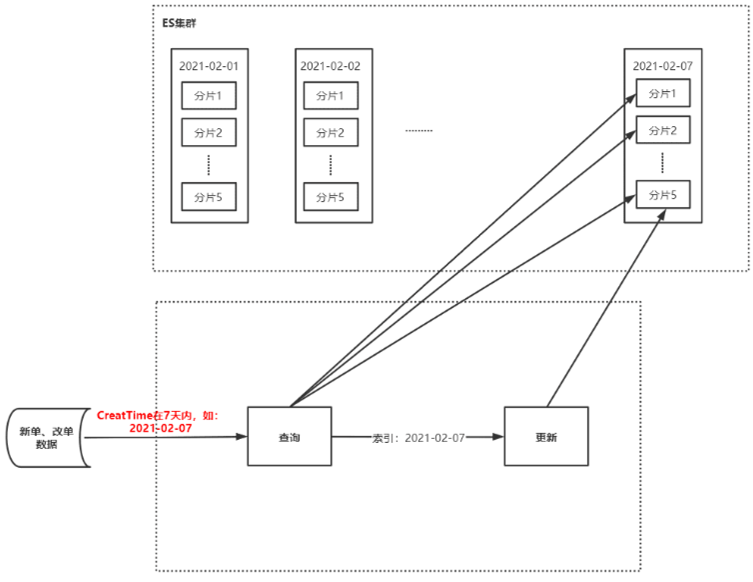
记一次ES查询优化
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/ES-Query-Optimization.html 背景 难得有数据留存,写一篇^_^ 原逻辑 ES接收新单、改单、状态数据(占总数据的70%),写入ES的7天索引中 ES存在以天为单位的7个索引(如:20210101~20210107,7个索引) 存储逻辑: 根据订单创建时间,保存到对应月日的索引内,如:1月1日的保存到20210101 如果不再最近7天内的特殊订单,那么会存到今天最新的一天的索引内 查询查询: 接收到查单请求后,根据订单创建时间,根据月日指定去查询这7个索引的某一个或多个 如果是在最近7天的,那么保存到该日期对应的索引内 如果在最近7天以外的订单,那么会保存到今天最新的一天的索引内 更新逻辑: 先查询出原来的订单,然后更新,更新后保存到原来的索引内 初步分析 监控问题分析 大数据监控显示:在双十一前后ES监控IO读写次数过高,出现读/写拒绝,CPU占用高,初步分析主要原因有以下: 量大:写入ES的数据...
dubbo调用流程
[半转载]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/dubbo/dubbo-call-flow.html 概要精简版流程 客户端从注册中心拉取和订阅服务列表 聚合服务列表,形成Invoker 客户端通过路由和负载均衡选择合适的服务提供者 将请求交给底层的I/O线程池处理 在I/O线程池中进行序列化和反序列化等操作 将请求交给业务线程池处理业务方法调用 Dubbo的调用流程主要在客户端完成,通过注册中心、路由、负载均衡等机制实现服务的发现和选择,然后通过底层的I/O线程池和业务线程池处理请求。这样的设计使得Dubbo具备高性能、高并发的特点,适用于分布式系统中的服务调用场景。 补充版流程 客户端启动时,会从注册中心拉取并订阅对应的服务列表。这些服务列表会被聚合成一个Invoker(调用器)。Cluster模块会将多个服务提供者聚合成一个Invoker。 在发起RPC调用之前,客户端会通过Directory#list方法获取服务提供者的地址列表,这些地址列表将被用于后续的路由和负载均衡操作。Dubbo内部还...
消息中间件-kafka
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/MQ/mq-kafka.html 1. 为什么 Kafka 快 1.1 通过生产和缓冲区减少网络开销 Kafka 的生产者发送消息时,会将多条消息打包为一个 batch(发送缓冲区)一起发送,等缓冲区大小达到阈值或者一定时间,批量发送,从而减少网络开销 1.2 根据不同 ack 配置,可以不刷盘、少刷盘就响应 ack ack=0:生产者发送消息后,不会等待 Broker 的响应,不保证消息是否到达 Broker ack=1:生产者发送消息后,等待 Leader Broker 接收到消息后,返回 ACK 响应 acks=all 或 acks=-1:生产者发送消息后,等待 Leader Broker 接收到消息,并且等待其他所有副本都成功复制消息(落盘),才会返回 ACK 响应 **注**: 节点接收到数据后不会立即刷盘,会先暂存到 pagecache 里,等到一定的大小或者时间后才会刷盘 1.3 零拷贝 正常 IO 需要经过 5 次读写才能从磁盘读取数据发送给消...
消息中间件-Rabbitmq
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/MQ/mq-rabbitmq.html RabbitMQ是一款开源的消息中间件,采用AMQP(高级消息队列协议)作为底层协议,提供了可靠的消息传递机制、灵活的路由方式以及多种消息发布/订阅模式等特性,被广泛应用于分布式系统、微服务架构等场景中 数据发布方式 RabbitMQ支持多种消息发布方式,主要包括以下几种: 1. P2P(点对点)模式 P2P模式是最简单的消息发布方式,即消息生产者直接将消息发送到指定的队列中,消费者通过消费该队列中的消息来获取数据 2. 发布/订阅模式 发布/订阅模式是指生产者将消息发送到一个交换机(exchange)中,而消费者则创建一个或多个队列并绑定到该交换机上,从而获取该交换机中的消息 在发布/订阅模式中,可以使用Fanout类型的exchange,该类型的交换机将消息广播给所有绑定到该交换机上的队列 3. Routing模式(路由模式) Routing模式是指生产者将消息发送到一个Direct类型的交换机中,交换机将消息交给符合...
Java I/O模型与系统I/O模型
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/system/IO-model2.html 接: IO模型 Java I/O模型与系统I/O模型的映射关系 Java的I/O模型是建立在底层系统I/O模型之上的,它通过对底层系统I/O调用的封装,提供了更高层次的抽象和统一的I/O接口。Java的I/O类库支持的I/O模型和底层系统I/O模型之间的映射关系如下: 阻塞式I/O模型 Java的I/O类库默认使用阻塞式I/O模型。在该模型下,I/O操作会一直阻塞,直到数据准备好或者操作完成才返回。对应的系统I/O模型是传统的阻塞式I/O模型。主要对应的系统I/O模型是Linux系统中的read(), write() 这里主要是各种Stream、Reader、Writer、Socket的读写,其中Socket为: 1234567891011121314ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();// 监听 8080 端口进来的 TC...
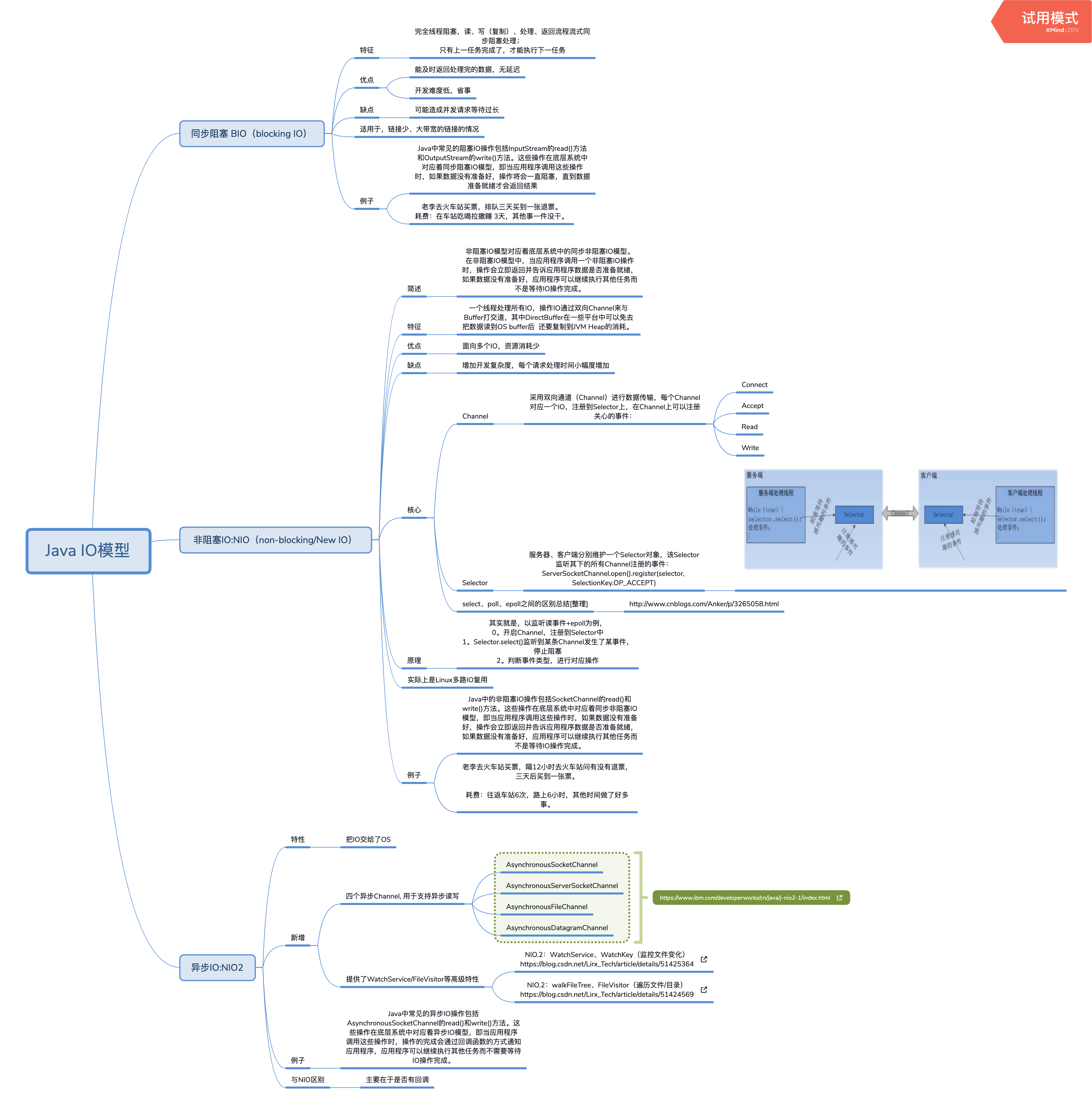
IO模型
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/system/IO-model.html 背景 服务器网络模型 这篇IO模型是《每天进步一点点》里的第一篇学习记录,真的是忘了看看了忘了。。其实不用记服务器的,大概理一下JAVA自己的就简单多了,这里稍微总结一下: JAVA IO模型 JAVA的IO模型分为BIO、NIO、AIO三种,其中BIO是阻塞IO,NIO是非阻塞IO,AIO是异步IO 阻塞IO模型: Java中常见的阻塞IO操作包括InputStream的read()方法和OutputStream的write()方法。这些操作在底层系统中对应着同步阻塞IO模型,即当应用程序调用这些操作时,如果数据没有准备好,操作将会一直阻塞,直到数据准备就绪才会返回结果。 非阻塞IO模型: Java中的非阻塞IO操作包括SocketChannel的read()和write()方法。这些操作在底层系统中对应着同步非阻塞IO模型,即当应用程序调用这些操作时,如果数据没有准备好,操作会立即返回并告诉应用程序数据是否准备就绪,如果数...
秒杀架构设计
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/framework-design/sec-kill-framework-design.html 常见的三类高并发场景 高并发压力主要来自,并发时出现大量锁冲突 1.细颗粒度操作-锁冲突少 如:QQ微信等即时通讯业务个人读个人自己的数据 数据结构 个人信息 user(uid…) 几十亿 个人的好友信息 friend(uid,friend_id…) 几百亿 个人的群 user_group(uid,group_id…) 几百亿 群成员 group_member(gid,uid…) 几千亿 个人消息(msg_id,uid…) 几千亿 群消息(msg_id,gid…) 几千亿 个人和群都是读写自己的数据 在高并发时(单个用户单位时间发出N个读写请求),锁冲突极小,每个【人】、【群】、【消息】只会锁住自己部分的消息 在出现IO瓶颈的时候 只需要进行水平分库 把【人】、【群】、【消息】进行切分 2.读多写少,存在少量写冲突 如:微博 自己的...

ES文档结构优化
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/es-structure-optimization.html 一个不错的优化: 背景 因为我们对订单的ES索引模板中,orderExtendInfoList存储多个扩展属性,用作外部订单号、二程运单号等信息的存储,业务上需要对其作为条件进行索引,为此我们把他设置为嵌套nested类型。 偶然学习发现这种嵌套nested类型会导致每个订单下的orderExtendInfo都会生成多个文档,导致索引数据量放大几倍,会导致查询性能下降,故重新设计进行优化。 优化ES存储订单数据的结构 把orderExtendInfoList打平并改为keyword类型(原来为嵌套类型), 内部额外存储一个作为索引用的值为原orderExtendInfo的key和value对应的Map 描述起来比较麻烦 大概是把下图左边的变成变成右边的 效果 4亿+数据量减少到只剩下5kw数据量,降低了十倍左右 查询时的CPU与内存压力均降低10%左右
微博Feed流读扩散设计
学习自58沈剑← [知识整理]根据个人理解整理后分享,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/Weibo-feed-design.html 什么是Feed流 Feed流即持续更新并呈现给用户内容的信息流 , 对于微博.微信朋友圈等业务刷新的数据都为Feed流 每条微博 朋友圈 为一条Feed 关键动作,关键数据 关键动作 关注 , 取关 发布Feed(朋友圈or微博) 获取自己主页的Feed流 核心数据 关系数据 Feed数据 难点 自己的主页由他人的Feed流组成 如果大家都是读写同一条Feed,会出现较大的读写冲突 造成系统的主要瓶颈 获取Feed流解决方案 模式有2种类: 拉模式 推模式 拉取模式 大致的数据结构 用户关系 用户的关注关系 user_follow(id,uid,follow_id…) 用户的粉丝关系 user_fans(id,uid,fans_id) //之所以要分成正反表是为了大数据量高并发情况下 可以做到分库 用户的消息列表(Feed) 用户...
Kafka延时队列方案探讨
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/Kafka-Delay-Queue.html 目前在用方案:直接重新丢回队列后面 实现逻辑 引入延迟消息消费服务,消费延迟消息 每条消息消费时,Sleep3秒(很长),再处理; 处理时判断是否到点,没到点的数据丢回kafka 优点 不引入新依赖(不依赖DB,不依赖其他第三方) 缺点 1. 处理效率慢,并发低 2. 延时时间不精准,颗粒度非常大 3. 浪费Kafka空间,同一数据在Kafka多次存储(其实Kafka底层是一种文件/文档存储,消息的消费只读不删) 优化方案1: 延迟消息存DB,通过Redis的zset结构支持 ### 实现逻辑 #### 1. 发送延时消息: > 延时消息发送到延时队列TopicA ### 2. 消费延时消息: > 延时程序(消费者)消费延迟队列的消息,把延时消息存入DB,再把[发送时间]+[延时消息在DB记录ID]作为zset设到Redis ### 3. 监控&&发送[到时的消息]: > 1....
Spring常见事件
[转载]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Spring/Spring-events.html ContextRefreshedEvent:表示ApplicationContext已经初始化或刷新完成时触发。通常在应用程序启动时使用,用来执行初始化操作 ContextStartedEvent:表示ApplicationContext已经启动时触发。通常在应用程序启动时使用,用来执行一些启动任务 ContextStoppedEvent:表示ApplicationContext已经停止时触发。通常在应用程序停止时使用,用来执行一些清理任务 ContextClosedEvent:表示ApplicationContext已经关闭时触发。通常在应用程序关闭时使用,用来执行一些清理任务 RequestHandledEvent:表示Web请求已经处理完成时触发。通常在Web应用程序中使用,用来记录日志或统计数据 ApplicationStartedEvent:表示Spring Boot应用程序已经启动完成时触发。通常在Spri...
线上ElasticJob堵塞问题排查
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Bug-Log-Optimization/elasticJob-bug-fix.html 背景 刚进新公司3天正逢双十一,领导生产补数出问题了,补数速度不稳定时快时慢,百万条数据补了好几个小时,之前都是几分钟搞定的,导致通了个宵; 早上我早到公司,领导截了个数据库的图给我,说交给我来看,然后刚通宵完的他就去开会汇报去了。。。我还没来得及熟悉环境,就被扔到了火坑里了,压力山大。。。 具体的过程没记录,这里只能凭回忆记录下了 问题描述 给我的截图大概长这样: 数据库分库号 需要补数的运单数量 分库0 12345 分库1 0 分库2 0 … *** 分库31 0 分库32 0 分库32 5w 分库33 4w 分库34 8w … *** 分库128 8w 知道的太少,跟同事了解业务,其实补数就是重推数据,把需要重推的单号记入表中,然后通过ElasticJob定时任务消费表中数据,实现重推数据 问题分析 没用过Ela...
docker部署zookeeper集群
1234// 查看config命令参数$ docker-compose -f zookeeper-compose.yml config --help// 校验配置文件,不打印$ docker-compose -f zookeeper-compose.yml config -q 启动zookeeper集群 12// -d 后台启动$ docker-compose -f zookeeper-compose.yml up -d 查看容器启动情况 1$ docker-compose -f zookeeper-compose.yml ps 查看zookeeper集群状态 12$ docker exec -it zoo1 /bin/sh/zoo1 # zkServer.sh status zookeeper-compose.yml 12345678910111213141516171819202122232425262728293031version: '3'services: zoo1: image: zookeeper restart...
docker容器中安装ping
apt-get update & apt-get install iputils-ping 安装ifconfig指令为apt-get install net-tools
docker部署redis集群(Sentinel版)
拉取Redis镜像 1docker pull redis 通过镜像启动容器(Redis集群实例*3 1主2从,集群部署完再设密码) 1234567docker run -it --name redis9000 -d -p 9000:6379 redis redis-server --requirepass 123456 --port 6379docker run -it --name redis9001 -d -p 9001:6379 redis redis-server --requirepass 123456 --port 6379docker run -it --name redis9002 -d -p 9002:6379 redis redis-server --requirepass 123456 --port 6379#docker run -it --name redis9003 -d -p 9003:6379 redis redis-server --requirepass 123456 --port 6379#docker run -it --name redi...
