文章
77
标签
40
分类
25
主页
归档
分类
标签
其他
关于
花火笔记
主页
归档
分类
标签
其他
关于
design
分类 - design
2025
2025-12-15
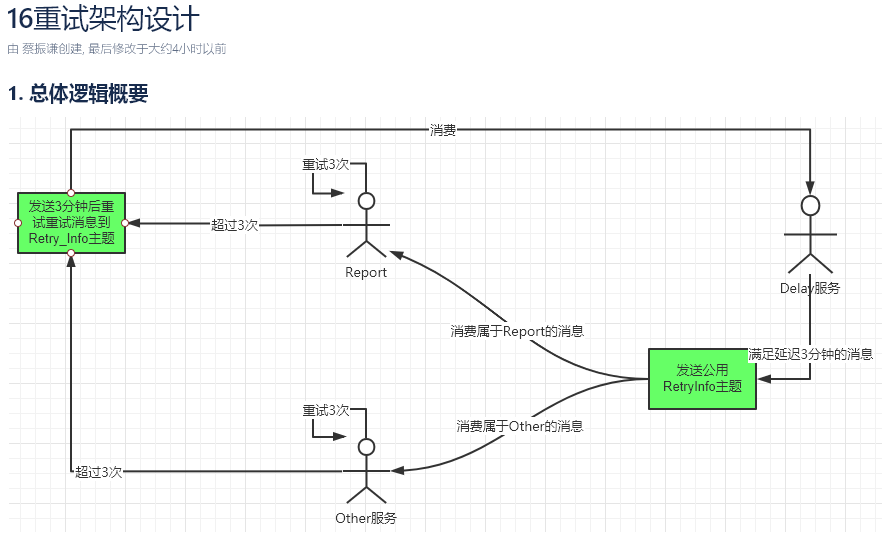
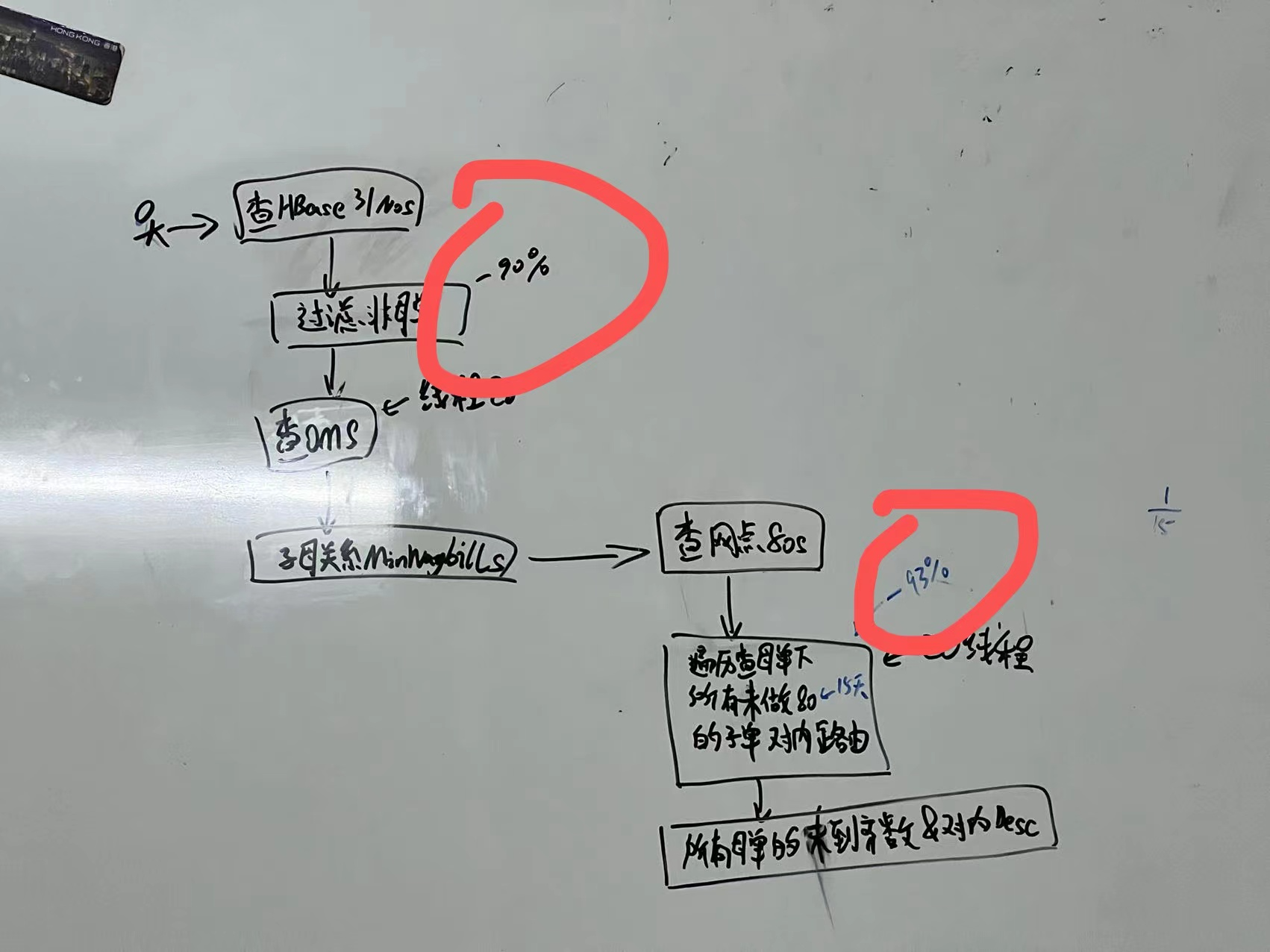
精准定时任务设计思路
2023
2023-05-11
关于上游同一数据大批量重复推送问题处理
2023-05-02
缓存强一致性方案
2022
2022-12-02
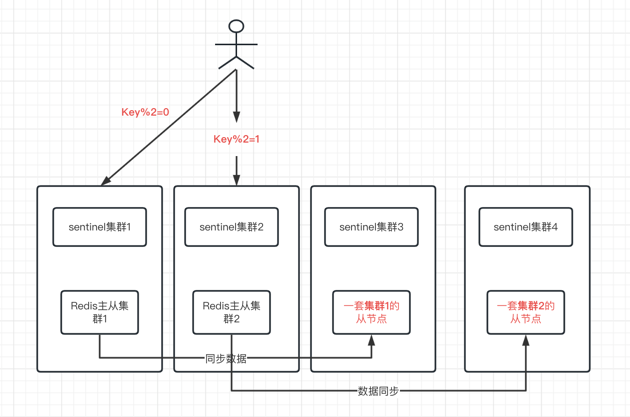
顺丰Redis-Sentinel架构部署
2022-09-12
Hystrix熔断优化
2022-09-12
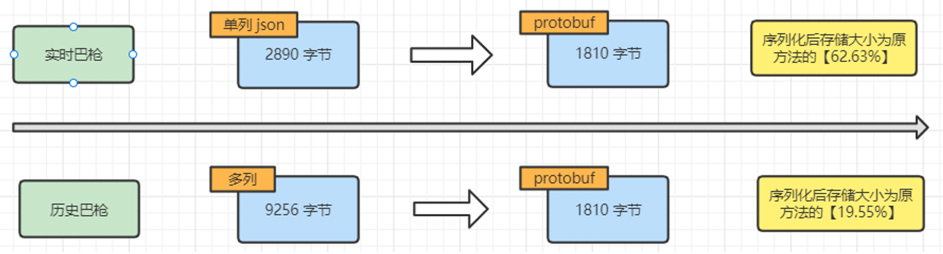
【Hbase优化_2】Hbase存储优化:Hbase数据压缩
2022-08-22
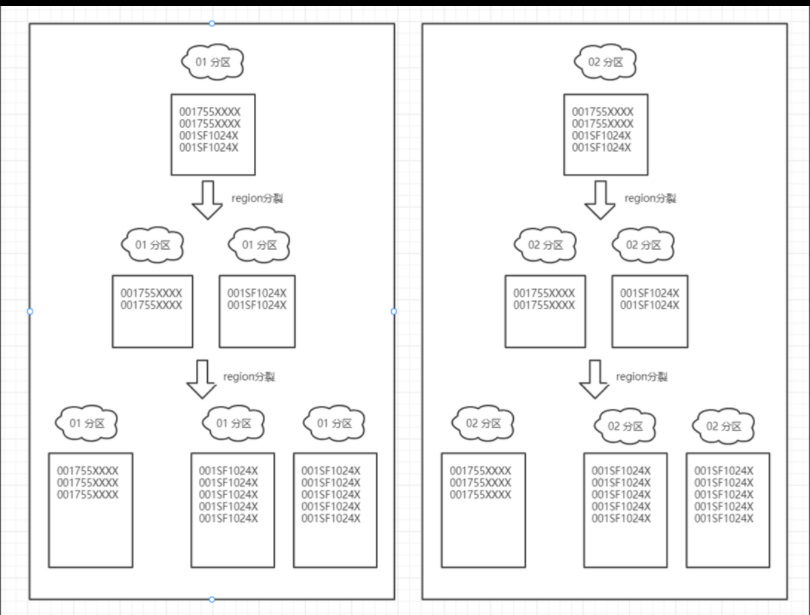
【Hbase优化_1】HBase 行键设计优化:解决数据倾斜问题
2022-08-02
(零拷贝)优化转发型文件下载
2022-06-12
通用kafka延迟队列生产实践
2022-02-12
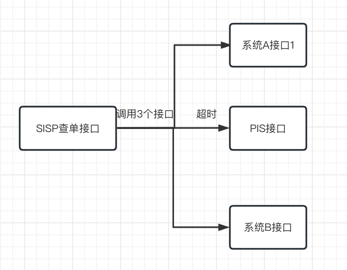
业务优化
1
2
花火
技术_转型之路
文章
77
标签
40
分类
25
Follow Me
公告
This is my Blog
最新文章
每天进步一点点 - English
2099-12-05
每天进步一点点 - 基础技术篇
2099-09-05
性能优化核心思想
2025-12-15
精准定时任务设计思路
2025-12-15
支付宝支付流程
2025-12-10
分类
Bug-Log&Optimization
5
Distributed
1
JVM
5
MQ
4
Make-A-Little-Progress-Every-Day
2
SA
2
Solution
1
Study
1
Spring
4
about
2
bookmarks
1
code-rules
9
database
3
design
18
dubbo
1
framework-design
1
idea
1
java
3
redis
4
system
5
web
1
部署
5
docker
5
redis
2
zookeeper
2
标签
SYSTEM
分布式
shell
BUG
REDIS
Analysis
zookeeper
架构设计
Consul
Kafka
MYCAT
每天进步一点点
Spring
KAFKA
JVM内存结构
高并发
读后感
算法
LOCK
Hbase
知识点整理
基础
MYSQL
Spring-Cloud
优化
DATABASE
redis集群
Code-Rule
JVM
MQ
白板
JAVA
idea
redis
ElasticSearch
docker
Mybatis
dubbo
Hystrix
部署
归档
十二月 2099
1
九月 2099
1
十二月 2025
3
五月 2023
2
四月 2023
1
十二月 2022
2
九月 2022
2
八月 2022
3
六月 2022
1
五月 2022
2
二月 2022
1
一月 2022
2
十月 2021
1
八月 2021
2
五月 2021
4
三月 2021
3
二月 2021
1
一月 2021
2
十月 2020
2
八月 2020
2
网站信息
文章数目 :
77
本站访客数 :
本站总浏览量 :
最后更新时间 :