
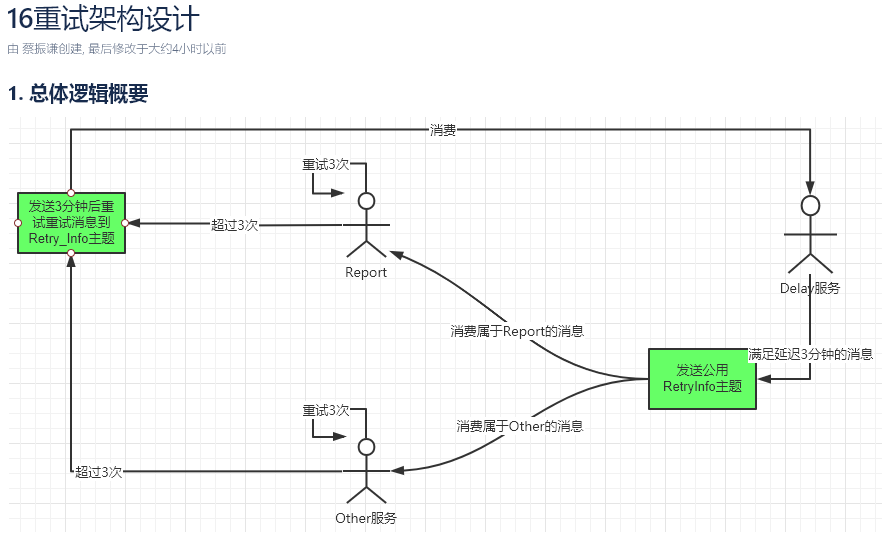
通用kafka延迟队列生产实践
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/general-kafka-delay-queue.html 接: Kafka延时队列方案探讨
生产故障分析:线程池配置错误导致的阻塞问题
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Bug-Log-Optimization/thread-pool-use-error.html 在生产环境中,我们遇到了一个由线程池配置错误导致的阻塞问题。本文将对这个问题进行详细分析,并提出相应的解决方案。 问题背景 后端在接收到前端用户请求后,会将请求分成4个线程交给一个线程池处理。这4个线程分别负责请求不同的查询接口,以获取查询结果。最后,将这些结果合并并同步返回给前端用户。 12345678910111213141516// 提交任务到线程池waybillNoQueryFuture = submitTask(waybillNoQueryService, waybillNo, currentUserName)orderInfoQueryFuture = submitTask(orderInfoQueryService, waybillNo, currentUserName)appointmentQueryFuture = submitTask(appointme...
生产故障分析:线程池配置错误导致的阻塞问题
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/SA/Solution/Production-Issue-ThreadPool-Misconfiguration.html 问题背景
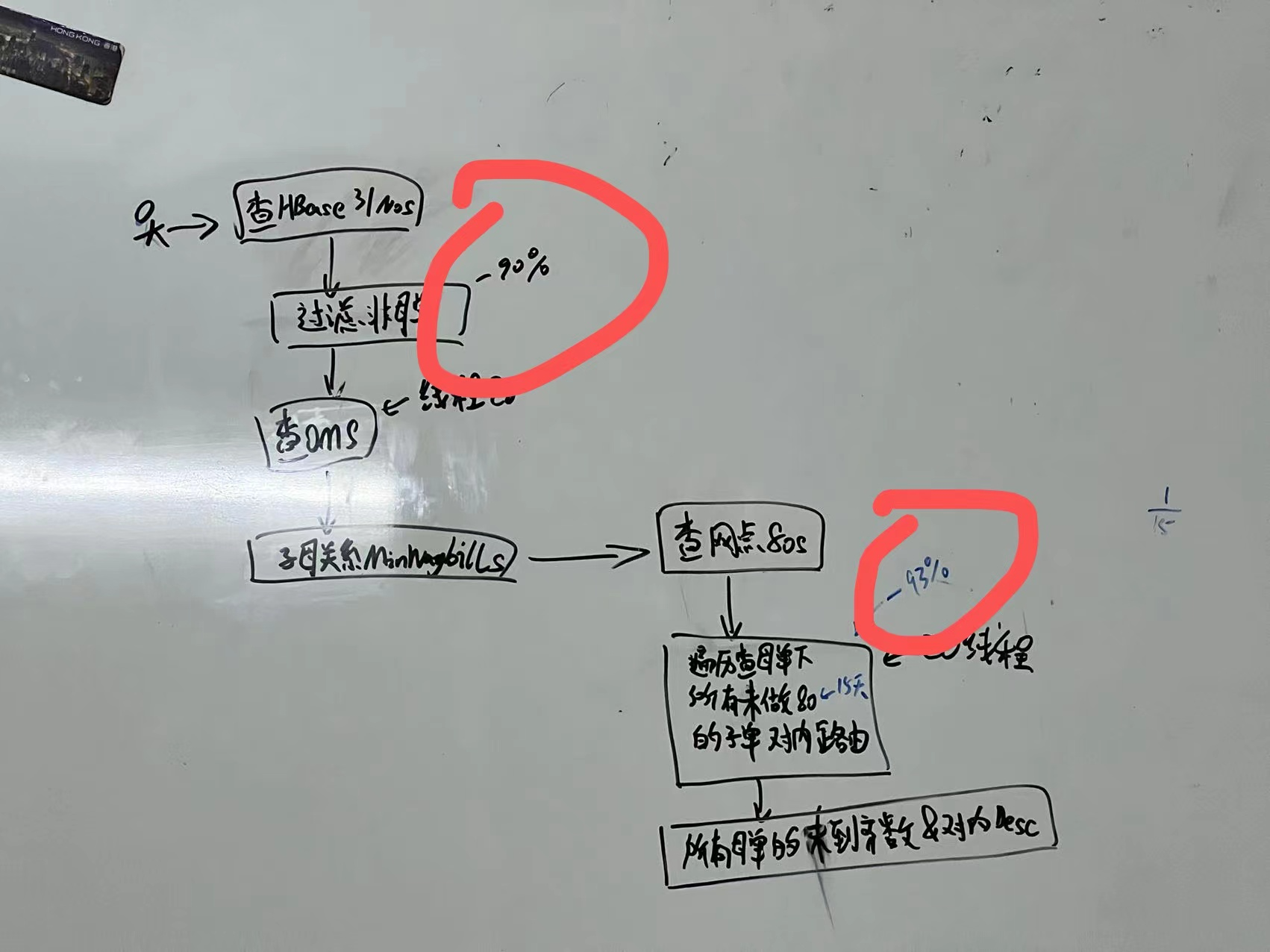
业务优化
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/business-optimization.html 背景实在太复杂了。。。简单放图,日后完善描述 一个报表需求由不可为,优化到可行并落地:通过多线程以及业务商讨优化,性能优化百倍以上,并满足业务需求。 除了技术手段外关键在于:通过与业务协商,控制查询范围到15天内、删除不必要的字段、筛选数据等各种业务手段减少查询量、http请求量实现。
Kafka整理
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/MQ/kafka-remark.html kafka为什么快 1. 通过生产和缓冲区减少网络开销 生产者发送消息时,会将多条消息打包为一个batch(发送缓冲区)一起发送,等缓冲区大小达到阈值或者一定时间,批量发送 2. 根据不同ack配置,可以不刷盘、少刷盘就响应ack ack=0 生产者发送消息后,不会等待Broker的响应,不保证消息是否到达Broker ack=1 生产者发送消息后,等待Leader Broker接收到消息后,返回ACK响应。 acks=all或acks=-1 生产者发送消息后,等待Leader Broker接收到消息,并且等待其他所有副本都成功复制消息(落盘),才会返回ACK响应。 注 节点接收到数据后不会立马刷盘,会先暂存到pagecache里,等到一定的大小或者时间后才会刷盘 3. 零拷贝 正常IO需要经过5次读写才能从磁盘读取数据发送给消费者 零拷贝可以实现内核态之间硬件的数据拷贝,只需要2~3次IO,尽可能不需要...
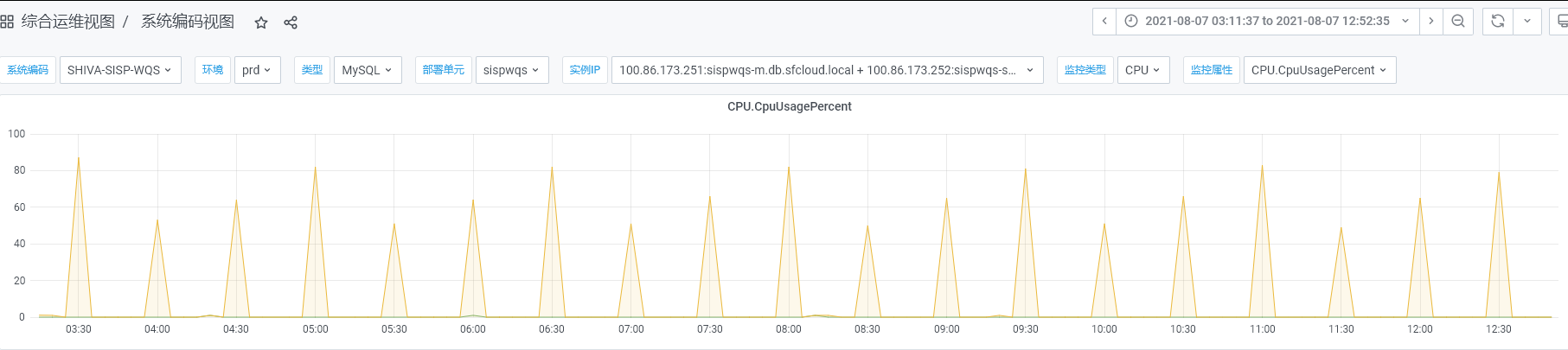
缓存密集加载导致数据库崩溃问题
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Bug-Log-Optimization/cache-load-database-crash.html 背景 SISP自己基本不存储业务数据,但是每个节点都需要本地缓存了一些网点、员工信息、月结用户信息等基础数据,生产监控发现数据库定期压力飙升,数据库CPU压力到达80+%如图: 用脚趾头分析 从图中可以看出,每天小时飙升一次,明显就是定时任务大批量查询数据库导致的,在SISP系统,也就只有加载缓存可能会导致 找到运维获取慢日志,发现大量的查询语句,如下: 12345SELECT DISTINCT nd.division_code AS city_code, nnd.dist_cn_name , nnd.dist_en_name FROM tm_new_district nd, tm_new_district nnd WHERE nd.division_code IN( SELECT DISTINCT t.CITY_CODE FROM t...
shell-系统优雅停机
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/system/system-graceful-shutdown.html 脚本 1234567891011#!/bin/bashecho "请输入进程ID:"read pidecho "正在尝试使用kill -15终止进程$pid ..."kill -15 $pidsleep 5 # 等待5秒,给进程清理和资源回收的时间if ps -p $pid > /dev/null; then # 如果进程仍然存在,则使用kill -9进行强制终止 echo "进程$pid 仍在运行,正在尝试使用kill -9强制终止 ..." kill -9 $pidfiecho "进程$pid 已终止"
垃圾回收器选型
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/JVM/jvm-gc.html 总揽 吞吐量和最短停顿时间本来就互相矛盾 Parallel Old追求的是吞吐量,CMS追求的是STW的最短 而G1通过把堆分成多个相对独立的Region块,并行的进行选择性的回收,实现一个两者兼顾的回收器 Parallel GC: 适用于吞吐量优先的场景 原理: 通过参数-XX:GCTimeRatio 设置垃圾回收时间占总时间的比例,默认值为99,即垃圾回收时间不超过1%,实现吞吐量优先 CMS(Concurrent Mark Sweep)GC: 适用于响应时间优先的场景 原理1:通过-XX:CMSInitiatingOccupancyFraction预留空间实现一边回收垃圾,一边执行业务逻辑,实现响应时间优先 原理2:通过并发标记等,实现尽可能低的停顿 缺点1: 内存使用率低,为了一边干活一边回收垃圾,预留了一定的内存 缺点2:产生碎片,虽然FullGC时候,但是运行期间会产生大量碎片 (新增)G1(Garbage...
报表JVM调优
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/JVM/report-jvm-optimize.html 忘记记录了。。凭记忆记录下😂,下面是大概流程 背景 之前上线的一个新报表项目,我们的报表服务主要通过定时任务异步生成报表,报表比较大,每次运行时长长,实时性要求较低。 但在生产环境普罗米修斯监控中,发现服务频繁进行GC,且GC前后释放的内存不多,GC期间CPU占用略高。但是GC时长看着很短,为了解决这个问题,我进行了一次针对报表服务的JVM调优 过程 1. 看监控 使用Prometheus监控JVM指标,并结合Grafana进行数据可视化。通过Prometheus收集报表服务的JVM指标,如GC情况、内存使用、线程状态等 发现回收间隔时间较短,且回收前后大部分时候释放的内存不是特别多,但有时候却特别多,看了下GC配置,G1+默认200ms的回收间隔,估计是这个时间间隔搞个鬼,不太适合我们的业务场景(报表比较大,每次运行时长长)。 2. jstat确认GC前后内存变化 1jstat -gc 12345 1000 ...
数据库数据倾斜
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/Bug-Log-Optimization/database-skew.html 其实改动不是很大,这里简单记录下 背景 OMS订单系统,日数据量较大平均近3kw/日,高峰达8kw+/日的订单需要存到数据库中(之前64库,现在扩到了128库); 运维后台监控看到,各个库的压力不一,江浙沪,京津冀,深圳755等地区对应的数据库压力很高,而其他地区的数据库压力很低; 分析 数据库通过mycat,以分库号字段进行分库,以内部订单号分表 内部订单号规则: 3位分库号+系统来源(2位)+MMDDHHmmssSSS+订单类型+6位随机数+1位校验码=26位 分库号生成规则为根据地区、网点进行生成; 因此,可以看出,同一地区的订单,分库号是一样的,因此,同一地区的订单,会落在同一个库中; 解决 直接粗暴修改分库号生成规则为0~127区间随机生成,因为原有订单的删、改、查最终都会带上原有的内部订单号,所以不会影响到历史数据,只是新的订单会落在不同的库中; 上线方案 因为是S级系统...
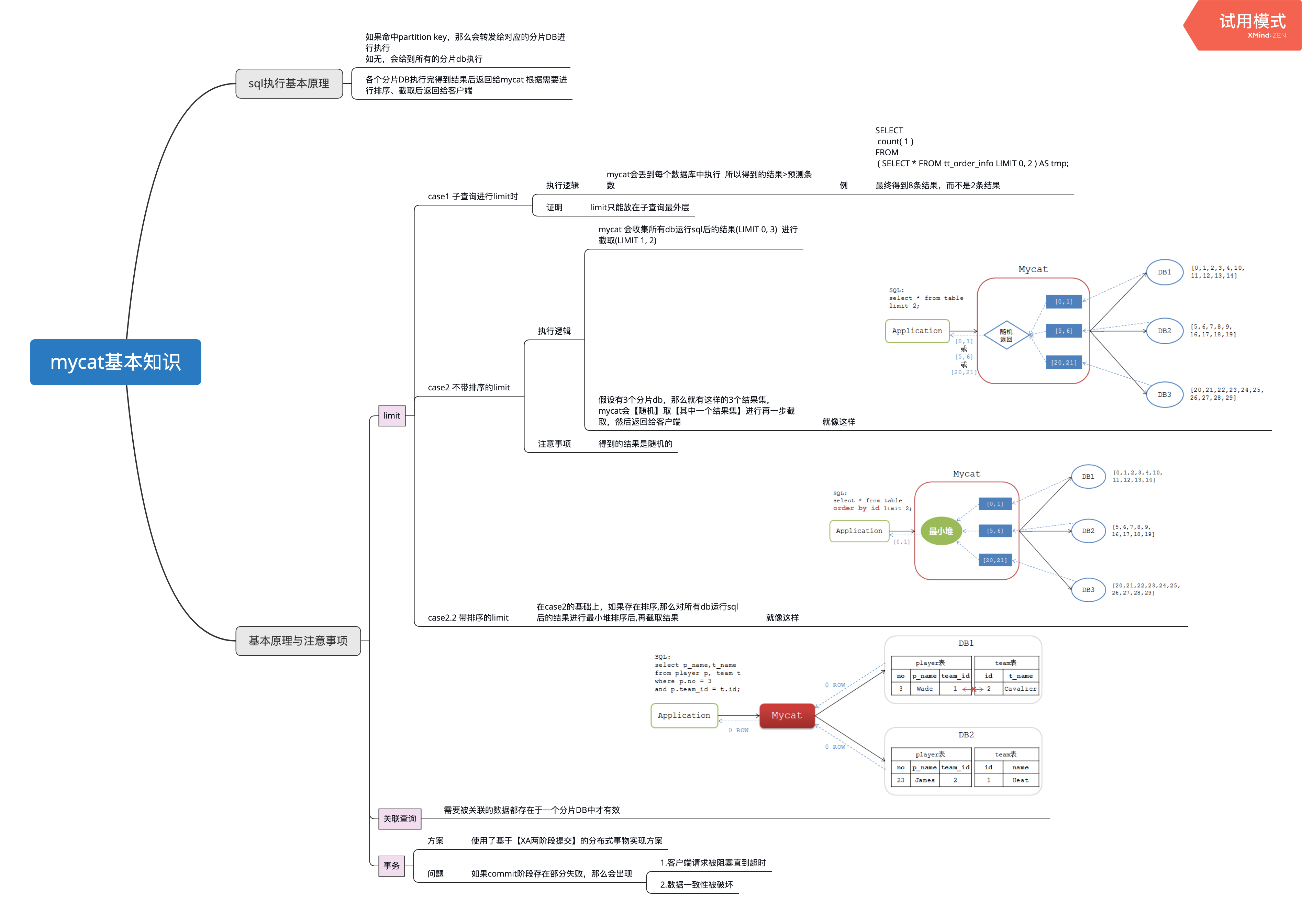
使用mycat后注意要点
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/database/careful-when-use-mycat.html 忙死,简单贴个笔记截图吧 主要就是注意一下mycat分发sql给到对应1~n个数据库,其数据库都会执行这一条sql,然后再去mycat那里聚合结果,所以要注意一下sql的写法 一些笔记
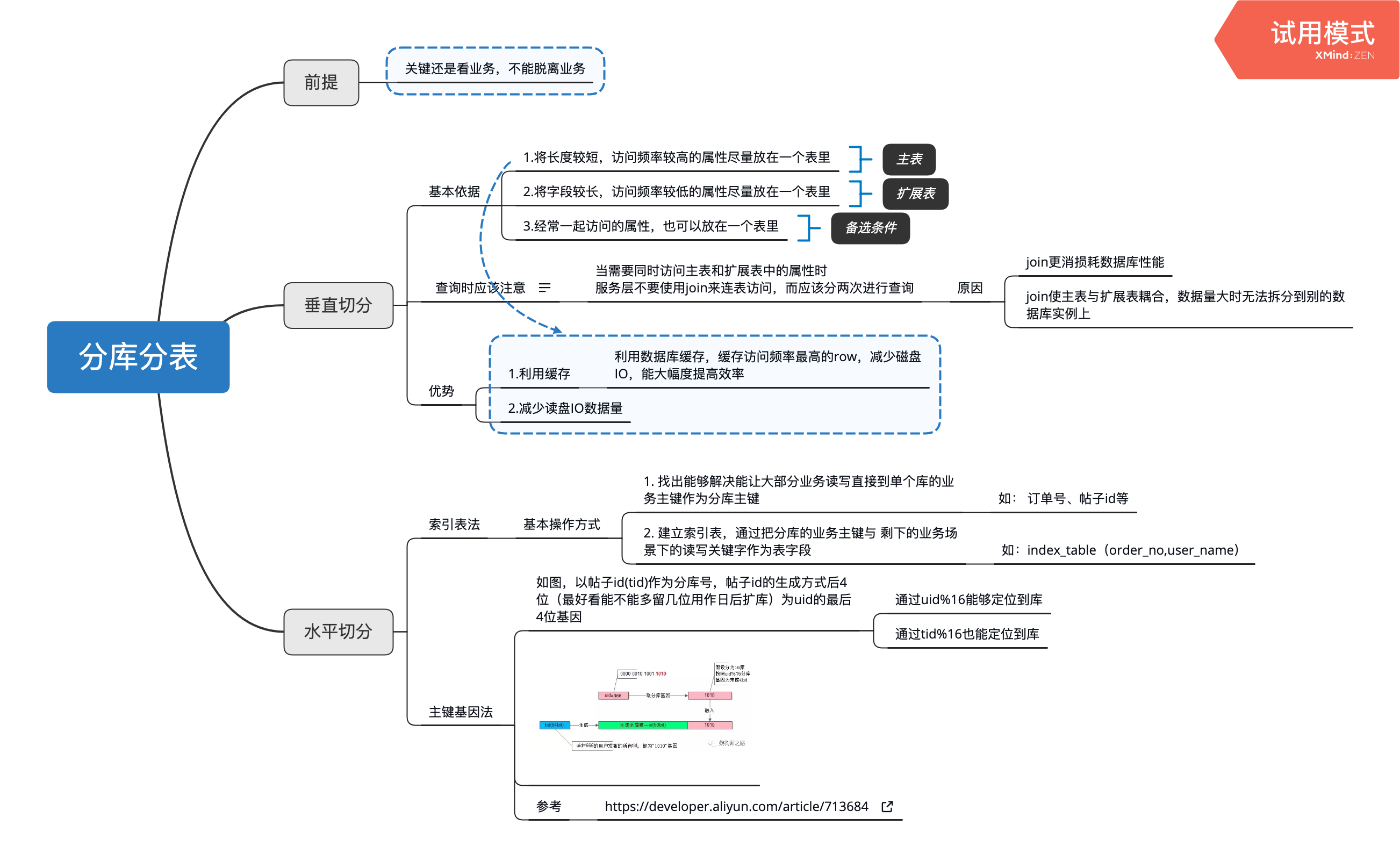
分库分表
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/database/sub_library_and_sub_table.html 学习自:单KEY业务,数据库水平切分架构实践 | 架构师之路 一些笔记 图中水平分库的基因法虽然好用,但是只支持2个字段的分库,如果要支持2个字段以上,那么就得使用索引表法了,缺点是需要多查一次表。
生产数据库扩库
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/database-scale.html 背景
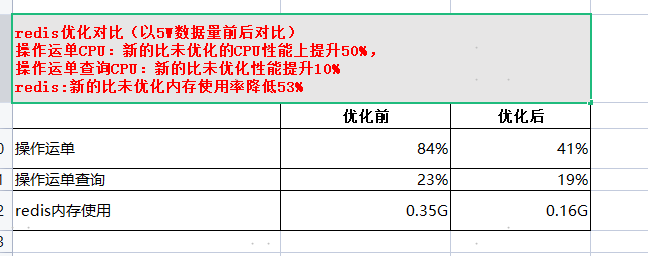
snappy压缩redis方案可行性验证
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/snappy-compress-redis.html Snappy压缩方案 研发环境(redis单节点,两个哨兵) 1. 压缩率 压缩前的redis内存: String类型保存1万份不同key,相同value的运单内存为119.61-1.02=118MB: Byte[]类型保存1万份不同key,相同value的运单内存为31.74-1.02=30MB: 结论:改造后的压缩率提升(118-30)/118=74% 2. cpu对比 1. 单线程1万次写入redis String类型,基本维持在5%以下: Byte[]类型,基本维持在5%以下: 结论:cpu对比无明显变化 2. 单线程一万次读取对比: String类型: Byte[]类型: 结论:cpu对比无明显变化 3. 耗时对比 单线程1万次写入redis耗时 单线程1万次读取redi耗时 String类型 135677ms 130027ms byte[]类型 12880...
Redis压缩方案设计--各种压缩方案单机的比较(CPU)
[原创]个人理解,请批判接受,有误请指正。转载请注明出处: https://heyfl.gitee.io/design/Redis-compress-design.html 1、 CPU性能对比(通过对比CPU时间) 对比论证: 选择序列化CPU使用率最低,约原来的16%~73%,其中FST序列化方式为原来的16%,速度最快 选择纯字符串压缩的方式因为是在原toJSON和parseObject的逻辑之间,再加入压缩逻辑,故性能比原生JSON会略差一些 (对比序列化&压缩方案)每轮十万次测试 压缩方案单轮测试耗时最高,为0.42s,约每次使用该方案消耗0.04ms,对比原方案单次多次0.01ms的CPU时间,故认为以上方案对性能的损耗问题可忽略 序列化方案单论测试耗时最低,为0.05s,约每次使用该方案可节约0.027ms的CPU时间,对比压缩方案,可节约0.037ms的CPU时间,故认为序列化对性能提升不高 总结 纯序列化方案占用CPU时间少,纯压缩方案占用CPU时间稍多,但是都对整体性能影响极小 2、使用序列化实践的方案(速度快,压缩...
